
Amazon Kinesis
- Amazon Kinesis は、大規模なストリーミングデータのリアルタイム処理を可能にします。
- Kinesis Streams は、特殊なニーズに合わせてストリーミングデータを処理または分析するカスタムアプリケーションの構築を可能にします。
- Kinesis Streams 機能
- データ・ストリーム用のハードウェア、ソフトウェア、またはその他のサービスのプロビジョニング、デプロイメント、継続的な保守を処理します。
- 必要なデータスループットのレベルでデータをストリーミングするために必要なインフラストラクチャ、ストレージ、ネットワーク、および構成を管理します。
- AWS リージョン内の3つの施設間でデータを同期的にレプリケートし、高可用性とデータの持続性を実現します。
- ストリームのレコードは、デフォルトではストリームに追加された時点から最大24時間保存されます。拡張データ保持を有効にすることにより、最大7日間に制限を引き上げることができます。
- クリックストリーム、アプリケーションログ、ソーシャルメディアなどのデータは、複数のソースから追加することができ、数秒以内に Amazon Kinesis アプリケーションへの処理が可能です。
- Kinesis は、レコードの順序を提供するだけでなく、複数の Kinesis アプリケーションに同じ順序でレコードを読み取りおよび/または再生する機能も備えています。
- Kinesis Streams は、データプロデューサからデータを迅速に移動し、データを連続的に処理し、データストアに出力する前にデータを変換し、リアルタイムのメトリックスとアナリティクスを実行したり、さらに複雑なデータストリームを派生させたりするのに便利です。
- ログとデータフィードの高速化: データプロデューサは、生成されるとすぐにデータを Kinesis Streams にプッシュし、データの損失を防ぎ、数秒以内に処理できるようにします。
- リアルタイムのメトリックスとレポート: メトリックスを抽出して、リアルタイムでデータからレポートを生成するために使用できます。
- リアルタイムデータ分析: リアルタイムストリーミングデータ分析を実行します。
- 複雑なストリーム処理: Kinesis アプリケーションとデータストリームの Directed Acyclic Graphs (DAG) を作成し、Kinesis アプリケーションを別の Amazon Kinesis Streamas に追加してさらに処理を行うことで、ストリーム処理の連続したステージを実現します。
- Kinesis の制限
- 最大24時間までのストリームのレコードをデフォルトで保存し、最長7日間まで拡張できます。
- 1つのレコード内のデータ blob (Base64 エンコーディング前のデータペイロード) の最大サイズは 1 MB です。
- 各シャードは、1秒あたり最大1000の PUT レコードをサポートできます。
- 各アカウントはリージョンごとに 10個 のシャードをプロビジョニングでき、さらにリクエストにより増加することができます。
- Amazon Kinesis はストリーミングビッグデータを処理するように設計されており、価格設定モデルでは PUT を重視することができます。
- Amazon S3 は、データを保存するためのコスト効率の高い方法ですが、リアルタイムでデータのストリームを処理するようには設計されていません
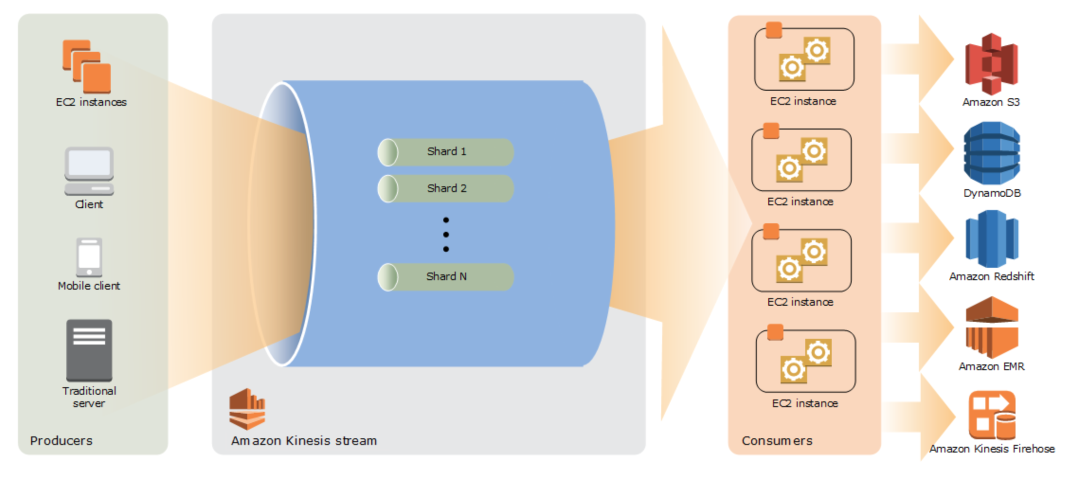
Kinesis Streams
- シャード
- ストリームはシャードで構成され、Kinesis Stream の基本スループット単位です。
- 各シャードは、1MB/秒のデータ入力と 2MB/秒のデータ出力の容量を提供します。
- 各シャードは、1秒あたり最大1000の PUT レコードをサポートできます。
- すべてのデータは24時間保存されます。
- 24時間のウィンドウ内でデータを再生する
- シャードは容量の制限を定義します。データスループットまたは PUT レコード数のいずれかによって制限を超えた場合、PUT データ呼び出しは ProvisionedThroughputExceeded 例外で拒否されます。
- この処理は、
- ストリームの入力データレートが一時的に上昇したために、データプロデューサ側で再試行を実行する
- シャード (リシャーディング) の数を動的にスケーリングして、PUT データ呼び出しが一貫して成功するのに十分な容量を提供する。
- レコード
- レコードは、Amazon Kinesis Stream に格納されているデータの単位です。
- レコードは、シーケンス番号、パーティションキー、およびデータ blob で構成されます。
- データ blob は、データプロデューサがストリームに追加する対象のデータです。
- データ blob の最大サイズ (Base64 エンコーディングの前のデータペイロード) は 1 MB です
- パーティションキー
- パーティションキーは、ストリームの異なるシャードにレコードを分離してルーティングするために使用されます。
- Amazon Kinesis Streams にデータを追加する際に、データプロデューサによってパーティションキーが指定される。
- シーケンス番号
- シーケンス番号は、各レコードの一意の識別子です。
- データプロデューサが PutRecord または PutRecords 操作を呼び出して Amazon Kinesis Streams にデータを追加する場合、シーケンス番号は Amazon Kinesis によって割り当てられます。
- 同じパーティションキーのシーケンス番号は、通常、時間の経過と共に増加します。PutRecord または PutRecords 要求の間の期間が長いほど、シーケンス番号が大きくなります。
Kinesis Streams コンポーネント
- Amazon Kinesis Streams へのデータは、PutRecord および PutRecords オペレーション、Kinesis プロデューサライブラリ (KPL)、または Kinesis Agent を介して追加できます。
- Amazon Kinesis Agent
- Amazon Kinesis Streams にデータを収集して送信する簡単な方法を提供する、あらかじめ構築された Java アプリケーションです。
- Web サーバー、ログサーバー、データベースサーバーなどの Linux ベースのサーバー環境にインストールできます。
- ディスク上の特定のファイルを監視し、Amazon Kinesis Streams に新しいデータを継続的に送信するように構成できます。
- Amazon Kinesis プロデューサーライブラリ (KPL)
- Amazon Kinesis Streams にデータを配置するのに役立つ、使いやすく、高度に構成可能なライブラリです。
- シンプルで非同期で信頼性の高いインターフェイスを提供することにより、最小限のクライアント・リソースで高プロデューサのスループットを迅速に実現できます。
- Amazon Kinesis Agent
- Amazon Kinesis アプリケーションは、Amazon Kinesis Streams からデータを読み込んで処理するデータコンシューマであり、Amazon Kinesis API または Amazon Kinesis クライアントライブラリ (KCL) を使用してビルドすることができます。
- Amazon Kinesis クライアントライブラリ (KCL)
- 複数の言語をサポートする事前に構築されたライブラリです。
- 特定のパーティションキーのすべてのレコードを同じレコードプロセッサに配信します。
- たとえば、カウント、集計、およびフィルタ処理を実行するために、同じ Kinesis Streams から複数のアプリケーションを読み込むことが容易になります。
- ストリーム・ボリュームの変更への適応、ロード・バランシング・ストリーミング・データの調整、分散サービスの調整、フォールトトレランスによるデータ処理などの複雑な問題を処理
- Amazon Kinesis コネクタライブラリ
- Amazon Kinesis Streams を他の AWS サービスやサードパーティツールと簡単に統合できるようにするための、あらかじめ構築されたライブラリです。
- Kinesis コネクタライブラリには、Kinesis クライアントライブラリが必要です。
- Amazon Kinesis Storm Spout は、簡単に Apache Storm と Amazon Kinesis Streams を統合することができます。事前に構築されたライブラリです。
- Amazon Kinesis クライアントライブラリ (KCL)
Kinesis 対 SQS
- Kinesis Streams は、ビッグデータのストリーミングのリアルタイム処理を可能にしながら、SQS は、メッセージを格納し、分散アプリケーションコンポーネント間でデータを移動するための信頼性の高いスケーラブルなホストキューを提供します。
- Kinesis は、レコードの順序を提供するだけでなく、複数の Amazon Kinesis アプリケーションに対して同じ順序でレコードを読み書きする機能とともに、SQS はデータの順序を保証せず、少なくとも1回のメッセージ配信を提供します。
- Kinesis は、デフォルトでは最大24時間のデータを保存し、SQS は最大4日までメッセージを保存し、デフォルトでは1分から14日まで設定できますが、コンシューマによって削除されたメッセージは消去されます。
- Kinesis と SQS の両方が、少なくとも1回のメッセージ配信を保証
- Kinesis は複数のコンシューマをサポートしていますが、SQS は一度に1つのコンシューマにのみメッセージを配信でき、複数のキューで複数のコンシューマにメッセージを配信する必要があります。
- Kinesis ユースケースの要件
- レコードの順序
- 数時間後に同じ順序でレコードを消費する能力
- 複数のアプリケーションが同じストリームを同時に使用できる機能
- 関連レコードを同じレコードプロセッサにルーティングする (ストリーミング MapReduce の場合と同様)
- SQS ユースケースの要件
- メッセージレベルの ack/fail と可視性タイムアウトのようなメッセージングセマンティクス
- SQS の能力を透過的に拡張することを活用する
- 読み取り時の同時実行/スループットの動的増加
- 個々のメッセージの遅延。これは遅延する可能性があります。
Kinesis 対 S3
| Amazon Kinesis | Amazon S3 | |
|---|---|---|
| スループット | 1000/シャードあたり | TPS は、write-read-once-many に最適化されたキー名に依存します |
| サイズ | PutRecord を使用した単一レコードと、PutRecords を使用して最大500個のバッチ入力 | 単一オブジェクト |
| パフォーマンス | PUTのレイテンシは 100ms まで | S3のリージョンとエンドポイントに依存する |
| コンシューマ | 順次読み込み(2MB) | 各オブジェクトを取得する必要がある |
| イベントオーダー | 順序付け(各シャードの内側に) | 組込み順序なし |
| チェックポイント分析 | シーケンス番号を使用 | シーケンスなし |
| PUT/GET操作のコスト | $ | $$$ |
AWS認定試験の練習問題
- 質問はインターネットから収集され、答えは自分の知識と理解に基づいてマークされます(これはあなたと異なる場合があります)。
- AWSサービスは毎日更新され、回答と質問はすぐに時代遅れになる可能性がありますので、それに応じて調査してください。
- AWSのアップデートのペースを追うためにAWS試験の質問は更新されないため、基礎となる機能が変更されても質問が更新されないことがあります。
- さらなるフィードバック、ディスカッション、修正を可能にします。
- 米国での配送トラックの GPS 座標を追跡するアプリケーションを配備しています。各配送トラックから3秒に1度座標が送信されます。複数のコンシューマからのこれらの座標のリアルタイム処理を可能にするアーキテクチャを設計する必要があります。データの取り込みを実装するには、どのサービスを使用する必要がありますか。
- Amazon Kinesis
- AWS Data Pipeline
- Amazon AppStream
- Amazon SQS
- あなたは非常に人気のテレビ番組の投票を収集するアプリケーションを展開している。何百万のユーザーがモバイルデバイスを使用して投票を送信します。投票は、リアルタイムの公共の集計のための耐久性、拡張性、および高可用性データストアに収集する必要があります。どのサービスを使用する必要がありますか。
- Amazon DynamoDB
- Amazon Redshift
- Amazon Kinesis
- Amazon SQS
- あなたの会社は、ペットのための健康的なライフスタイルを促進する家族を支援するために生体情報を収集する次世代ペット用首輪を開発する過程にあります。各首輪は、Web ポータルの管理を介してペットの所有者と獣医に戻って健康トレンド情報を提供するデータを処理し、分析するコレクションプラットフォームに2秒ごとに JSON 形式でバイオメトリックデータの 30KB をプッシュしますあなたを任務としている収集プラットフォームを設計し、次の要件を満たしていることを確認します。インバウンド生体データのリアルタイム分析機能を提供する生体認証データの処理は、非常に耐久性があり、伸縮性があり、並行していることを確認します。分析処理の結果は、データマイニングのために永続化する必要があります。以下に概説するアーキテクチャは、コレクションプラットフォームの初期要件を満たしていますか。
- S3 を使用して受信センサーデータを収集する毎日のスケジュールされたデータパイプラインを使用して S3 からデータを分析し、結果を Redshift クラスターに保存します。
- Amazon Kinesis を利用して、受信センサーデータを収集し、Kinesis クライアントとデータを分析し、EMR を使用して Redshift クラスターに結果を保存します。(リンク参照)
- SQS を活用して受信センサーデータを収集する Amazon Kinesis で SQS からデータを分析し、その結果を Microsoft SQL Server RDS インスタンスに保存します。
- EMR を利用して受信センサーデータを収集し、Amazon Kinesis で EMR からデータを分析し、DynamoDB に結果を保存します。
- お客様は、ログ・ストリーム (アクセス・ログ、アプリケーション・ログ、セキュリティ・ログなど) を1つのシステムに統合することを心がけています。統合後、お客様は、ヒューリスティックに基づいて、これらのログをリアルタイムで分析したいと考えています。お客様は、過去12時間から抽出されたデータ・サンプルに戻る必要があるヒューリスティックを検証する必要があります。お客様の要件を満たすための最善の方法は何ですか?
- すべてのログイベントを Amazon SQS に送信します。EC2 サーバーの自動スケーリンググループをセットアップして、ログを使用し、ヒューリスティックを適用します。
- Amazon Kinesis にすべてのログイベントを送信するログにヒューリスティックを適用するクライアントプロセスを開発します (リアルタイム分析を実行し、7日間に拡張可能な24時間データを格納できます)
- カスタムログを受信するように Amazon CloudTrail を構成し、EMR を使用してログをヒューリスティックに適用する (CloudTrail は監査のみ)
- EC2 syslogd サーバーの自動スケーリンググループをセットアップし、ログを S3 に保存します電子カルテにヒューリスティックを適用する (EMRはバッチ分析用)
- ウェブサイト上で顧客のクリックストリームデータを分析し、行動分析を行うことができるようにする必要があります。顧客は、顧客がクリックしたページと広告の順序を知る必要があります。このデータは、ユーザーがサイトをクリックして粘着性を高め、広告をクリックしてページレイアウトを変更するためにリアルタイムで使用されます。キャプションの要件を満たし、このデータを分析するオプションはどれですか。
- URL ストアによるウェブログのクリックを Amazon S3 に記録し、EMR で分析します。
- Amazon Kinesis にセッションごとに web クリックをプッシュし、Kinesis ワーカーを使用して動作を分析する
- クリックイベントを Amazon Redshift に直接書き込み、SQL で分析する
- web クリックをセッションごとに Amazon SQS キューに発行する男性は、定期的にこれらのイベントを Amazon RDS にドレインし、SQL で分析します。
- ソーシャルメディア監視アプリケーションでは、AWS Elastic Beanstalk で実行されている Python アプリを使用して、ツイート、Facebook のアップデート、RSS フィードを Amazon Kinesis Streams に挿入します。2番目の AWS Elastic Beanstalk アプリは、Amazon DynamoDB テーブルに主要なパフォーマンスインジケータを生成し、ダッシュボードアプリケーションに電力を供給します。このアプリケーションのデータ損失を防ぐための最も効率的なオプションは何ですか。
- DynamoDB テーブルを別のリージョンにレプリケートするには、AWS データパイプラインを使用します。
- 2番目の AWS Elastic Beanstalk アプリを使用して、Kinesis データのバックアップを Amazon EBS に保存し、Amazon EBS ボリュームからスナップショットを作成します。
- 別のアベイラビリティーゾーンに2番目の Amazon Kinesis Streams を追加し、AWS Data Pipeline を使用して Kinesis Streams 間でデータをレプリケートします。
- Amazon Kinesis S3 コネクタを使用して Amazon Kinesis から Amazon S3 にデータをアーカイブする3番目の AWS Elastic Beanstalk アプリを追加します。
- 2つのシステム間で API 呼び出しをリアルタイムでレプリケートする必要があります。API 呼び出しイベントのバッファーおよびトランスポート機構として使用するツールを選択してください。
- AWS SQS
- AWS Lambda
- AWS Kinesis(aws キネシスはイベントストリームサービスです。ストリームはバッファとして機能し、システム間でのトランスポートを順番にプログラム可能なイベントにすることができるため、システム間での API 呼び出しのレプリケーションに最適です)。
- AWS SNS
- 適切に構造化されたデータに対してアドホックなビジネス分析クエリを実行する必要があります。データは常に高い速度で入ってきます。ビジネスインテリジェンスチームは SQL を理解できます。最初にどの AWS サービスを参照する必要がありますか。
- Kinesis Firehose + RDS
- Kinesis Firehose + Redshift (Kinesis Firehose は、ストリーミングデータを集約し、Redshift に挿入するためのマネージサービスを提供します。RedShift は、SQL 準拠のワイヤプロトコルを使用して、構造化されたデータに対するアドホッククエリもサポートしているため、ビジネスチームはこのシステムを簡単に採用できます。リンク参照)
- Hive を使用した EMR
- Apache SPARK が稼働している EMR
リファレンス
- Amazon Kinesis 開発者ガイド
- AWS Black Belt Online Seminar 2017 Amazon Kinesis SlideShare / オンデマンドセミナー

Jayendra’s Blog
この記事は自己学習用に「AWS Kinesis – Certification(Jayendra’s Blogより)」を日本語に訳した記事です。