
Amazon EMR
- Amazon EMR は、EC2 および S3 の web スケールインフラストラクチャ上で実行されているホスト型 Hadoop フレームワークを利用する Web サービスです。
- EMR は、企業、研究者、データアナリスト、および開発者が、膨大な量のデータを簡単かつコスト効率よく処理できるようにします。
- EMR
- オープンソースである分散データ処理エンジンとして Apache Hadoop を使用し、コモディティハードウェアの大規模クラスタで実行されるデータ集約型の分散アプリケーションをサポートする Java ソフトウェア
- 大量のデータを迅速かつ効率的に処理するための問題に最適
- Hadoop クラスターまたはコンピューティング容量の時間のかかるセットアップ、管理、またはチューニングを心配することなく、大きなデータを処理したり分析したりすることに焦点を当てることができます。
- Web インデックス作成、データマイニング、ログファイル分析、機械学習、財務分析、科学シミュレーション、バイオインフォマティクス研究などのアプリケーションに対して、データ集約型のタスクを実行することができます。
- クラスタを起動するための web サービス・インタフェースを提供し、クラスタに対する処理負荷の高い計算を監視
- 使用例がリアルタイムで処理する場合や、数分以内に Apache Spark またはストームがより良いオプションになる場合に、一般的な処理時間の期間を数時間で測定するバッチ処理フレームワークです。
- EMR はオンデマンド、スポット、リザーブドインスタンスをシームレスにサポート
- EMR は、同じ EC2 アベイラビリティーゾーン内の特定のクラスタのすべてのノードを起動し、より高いデータアクセス速度を提供するため、パフォーマンスが向上します。
- EMR は、標準、高 CPU、高メモリ、クラスタコンピューティング、高 i/o、高ストレージなど、さまざまな EC2 インスタンスタイプをサポートしています。
- 標準インスタンスには、ほとんどの汎用アプリケーションに適した CPU 比率のメモリがあります。
- 高 CPU インスタンスはメモリ (RAM) よりも比例して cpu リソースを消費し、計算負荷の高いアプリケーションに適しています。
- 高メモリインスタンスは、高スループットアプリケーション用の大きなメモリサイズを提供します。
- クラスタコンピューティングインスタンスは、ネットワークパフォーマンスの増加に比例して高い CPU を持ち、高性能コンピューティング (HPC) アプリケーションやその他の要求の厳しいネットワークバインドアプリケーションに適しています。
- 高ストレージ・インスタンスは24台のディスクに 48 TB のストレージを提供し、データ・ウェアハウスやログ処理などの非常に大きなデータ・セットへのシーケンシャル・アクセスを必要とするアプリケーションに最適です。
- 時間単位での EMR 料金すなわち、クラスタが実行されると、料金は全体の毎時適用されます。
- EMR は CloudTrail と統合して AWS API 呼び出しを記録
NOTE: 主にSolution Architect Professional 試験のトピック
EMR アーキテクチャ
- Amazon EMR は、データ処理エンジンとして、業界で実証済みのフォールトトレラント Hadoop ソフトウェアを使用します。
- Hadoop はオープンソースのJavaソフトウェアであり、コモディティハードウェアの大規模クラスタ上で実行されるデータ集約型分散アプリケーションをサポートします。
- Hadoop は、データを複数のサブセットに分割し、各サブセットを1つ以上の EC2 インスタンスに割り当てます。したがって、EC2 インスタンスがデータの1つのサブセットの処理に失敗した場合、別の Amazon EC2 インスタンスの結果を使用できます。
- EMR は、マスターノード、1つ以上のスレーブノードで構成されています
- マスターノード
- EMR は現在、マスターノードまたはマスターノードの状態回復の自動フェールオーバーをサポートしていません
- マスターノードがダウンした場合、EMR クラスターは終了し、ジョブを再実行する必要があります。
- スレーブノード-コアノードとタスクノード
- コアノード
- Hadoop 分散ファイルシステム (HDFS) を使用して永続的なデータをホストし、Hadoop タスクを実行する
- 既存のクラスタでの増加が可能
- タスクノード
- Hadoop タスクのみを実行する
- 既存のクラスタで増減することができます。
- EMR はスレーブ障害に対してフォールトトレラントであり、スレーブノードがダウンした場合にジョブの実行を継続します。
- 現在、EMR は障害が発生したスレーブを引き継ぐために別のノードを自動的にプロビジョニングしません
- コアノード
- マスターノード
- EMR は、可能なブートストラップアクションをサポートします
- ユーザーは、クラスターの実行前にカスタムセットアップを実行する方法を使用します。
- クラスタを実行する前に、ソフトウェアのインストールまたはインスタンスの構成に使用できます。
EMR セキュリティ
- EMR クラスターは、マスタとスレーブの異なるセキュリティグループから開始されます。
- マスターセキュリティグループ
- サービスと通信するためのポートが開いています。
- SSH ポートを開いて、起動時に指定されたキーを使用してインスタンスに直接 SSH を許可します。
- スレーブセキュリティグループ
- マスターインスタンスとの対話のみを許可します。
- スレーブノードへの SSH は、マスタノードとスレーブノードの間で SSH を実行することで実行できます。
- セキュリティグループは、異なるアクセス規則で構成できます。
- マスターセキュリティグループ
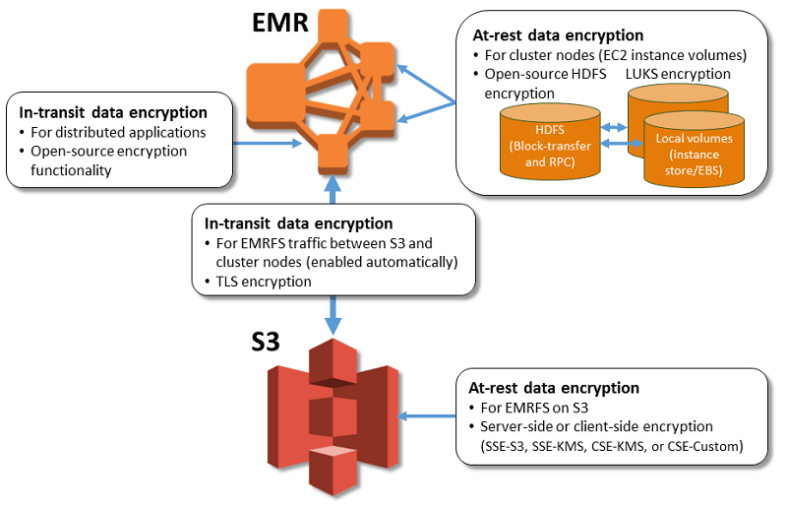
- EMR はセキュリティ構成の使用を可能にします。
- これは、データの残りの部分を暗号化するのに役立ちます, 転送中のデータ, またはその両方
- EMR ファイルシステム (EMRFS)、ローカルディスク暗号化、および転送中の暗号化による S3 暗号化の設定を指定するために使用できます。
- 再利用可能なクラスタ構成ではなく EMR に格納されます。
- AWS KMS によって管理されるキー、S3 によって管理されるキー、および提供するカスタムプロバイダからのキーと証明書など、いくつかのオプションから選択できる柔軟性を提供します。
- EMRFS を使用した S3 保存データの暗号化
- EMRFS は、サーバー側 (SSE-S3、SSE-KMS) とクライアント側の暗号化 (CSE-KMS または CSE-カスタム) をサポートしています。
- EMRFS による S3 SSE および CSE の暗号化は、相互に排他的です。どちらか1つを選択することができますが、両方ではない
- トランスポート層セキュリティ (TLS) は、EMR クラスターノードと S3 間の転送中に EMRFS オブジェクトを暗号化します。
- ローカルディスク保管データの暗号化
- オープンソースの HDFS 暗号化
- HDFS は分散処理中にクラスタインスタンス間でデータを交換し、インスタンスストアボリュームとインスタンスにアタッチされた EBS ボリュームにデータを読み書きします。
- オープンソースの Hadoop 暗号化オプションが有効になっている
- セキュア Hadoop RPC は、簡易認証セキュリティ層 (SASL) を使用する “プライバシー” に設定されています。
- HDFS ブロックデータ転送のデータ暗号化は true に設定されており、AES 256 暗号化を使用するように構成されています。
- LUKS. HDFS 暗号化に加えて、Amazon EC2 インスタンスストアボリューム (ブートボリュームを除く) と、アタッチされた Amazon EBS ボリュームのクラスタインスタンスは、LUKS を使用して暗号化します。
- オープンソースの HDFS 暗号化
- 転送中のデータ暗号化
- 2つの方法のいずれかで、転送中の暗号化に使用される暗号化アーティファクト:
- S3 にアップロードする証明書の zip ファイルを提供する
- または暗号化アーチファクトを提供するカスタム Java クラスを参照する
- 2つの方法のいずれかで、転送中の暗号化に使用される暗号化アーティファクト:
EMR クラスターの種類
- EMR には2つのクラスタタイプがあり、一時的と永続的
- 一時 EMR クラスタ
- 一時 EMR クラスターは、ジョブまたはステップ (一連のジョブ) が完了したときにシャットダウンするクラスタです。
- 一時 EMR クラスターが使用できるシチュエーション
- 1日あたりの EMR 処理時間の合計数 < 24 時間と、使用されていないときにクラスターをシャットダウンすることが有益です。
- HDFS をプライマリデータストレージとして使用する。
- ジョブ処理は集中的で反復的なデータ処理です。
- 永続 EMR クラスター
- 永続 EMR クラスターは、データ処理ジョブが完了した後も引き続き実行されます
- 永続 EMR クラスターが使用できるシチュエーション
- 多くの場合、前のジョブの後でクラスタを実行しておくと有益な処理ジョブが実行されます。
- 処理ジョブには、互いに入力出力の依存関係があります。
- まれに、S3 ではなく HDFS にデータを保存する方が費用対効果が高い場合
EMR のベストプラクティス
- データ移行
- 2つのツール – S3DistCp と DistCp – ローカル(データセンター) HDFS ストレージに格納されたデータを S3 に、S3 から HDFS に、S3 とローカルディスク(非HDFS)を S3 に移動することができます。
- AWS のインポート/エクスポートおよびダイレクトコネクトは、データの移動にも考慮することができます。
- データ収集
- Apache Flume は、大量のログデータを効率的に収集、集約、および移動するための、分散型で信頼性が高く利用可能なサービスです。
- Flume エージェントは、データソース(Webサーバー、アプリケーションサーバーなど)にインストールすることができ、コレクターに提供されたデータは、S3 や HDFS などの永続ストレージに保存することができます。
- データ集約
- データ集約とは、個々のデータレコード (ログレコードなど) を収集し、それらをデータファイルの大規模なバンドルに結合する技法を指します。小さなファイルから大きなファイルを作成する
- EMR が実行される Hadoop は、通常、多くの小さなファイルと比較して、より少ないサイズの大きなファイルでパフォーマンスが向上します。
- Hadoop は、複数のノード上の HDFS 上のファイルを分割し、S3 のデータは、HTTP 範囲ヘッダークエリを使用して、並列処理をサポートすることでパフォーマンスを向上させるファイルを分割します。
- Flume と Fluentd のようなログコレクターは、最終的な宛先 (S3 または HDFS) にコピーする前にデータを集計するために使用することができます。
- データの集計には次の利点があります
- AWS へのデータのアップロードに必要な回数を減らすことで、データ取り込みのスケーラビリティを向上
- S3 (または HDFS) に格納されているファイルの数を削減し、データ処理時のパフォーマンスを向上します。
- 圧縮率を大きくすることにより、高圧縮ファイルを圧縮すると、多数の小さいファイルを圧縮するよりも効果的です。
- データ圧縮
- データ圧縮は、入力時にも、マッパーからの中間出力にも使用できます。
- データ圧縮によって
- ストレージ・コストの削減
- データ転送のための低帯域幅コスト
- データ保存場所、マッパー、および減速機間のデータの移動によるデータ処理性能の向上
- EMR がディスクに書き込むデータを圧縮することによるデータ処理パフォーマンスの向上、すなわちディスクへの書き込みによるパフォーマンスの向上を実現する頻度が低い
- gzip のような圧縮手法がサポートしていないため、データ圧縮は Hadoop のデータ分割ロジックに影響を与える可能性がある
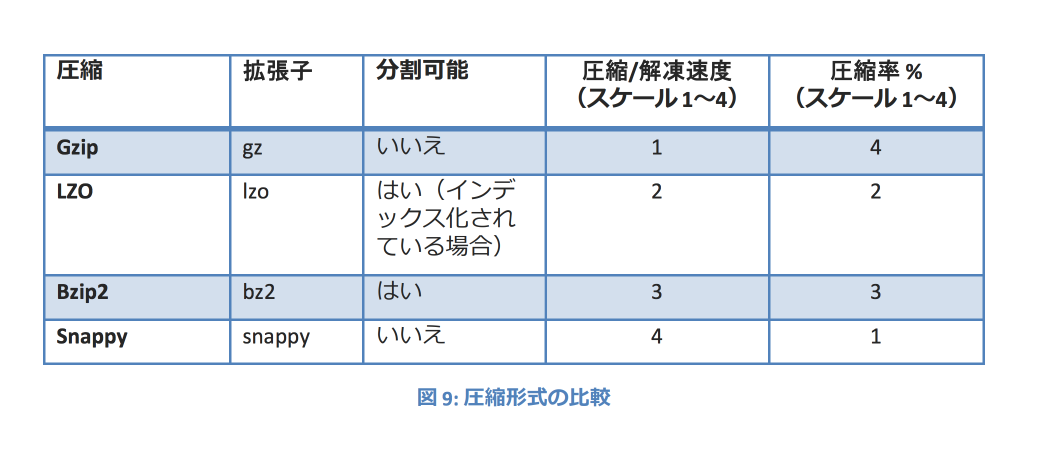
- データのパーティション分割
- データのパーティション分割は、データの最適化に役立ち、データの一意のバケットを作成し、データ処理ジョブがデータセット全体を読み取る必要をなくすことができます。
- データのパーティション分割が可能
- データ型 (時系列)
- データ処理頻度 (1 時間あたり、1日あたりなど)
- データアクセスとクエリパターン (時間のクエリと地理的位置のクエリ)
- コストの最適化
- AWS は EC2 インスタンスに対して異なる価格設定モデルを提供
- オンデマンドインスタンス
- 一時 EMR ジョブを使用する場合や、EMR 時間の使用量が 17% 未満の場合に適したオプションです
- リザーブドインスタンス
- 永続 EMR クラスターに適したオプションであるか、または EMR 時間の使用量がより多くの費用対効果であるとして 17% 以上である場合
- スポットインスタンス
- 計算能力を追加するためのコスト効率の高いメカニズムが可能
- S3 でデータが保持される場所で使用できます。
- タスクノードで余分なタスク容量を追加するために使用できます。
- マスターノードには適さず、クラスタが失われ、コアノード (データノード) はデータをホストするため、失われた場合は HDFS クラスタのリバランスに回復する必要があります。
- オンデマンドインスタンス
- アーキテクチャパターンは、使用することができます
- オンデマンドまたはリザーブドインスタンスでマスターノードを実行します (永続 EMR クラスターを実行している場合)
- オンデマンドまたはリザーブドインスタンスを使用して、コアノード上の EMR クラスターの一部を実行
- スポットインスタンスを使用するタスクノード上のクラスタの残りの部分
- AWS は EC2 インスタンスに対して異なる価格設定モデルを提供
EMR – S3 対 HDFS
- S3 にデータを格納すると、いくつかの利点があります
- 固有の機能の高可用性、耐久性、ライフサイクル管理、データの暗号化と Glacier へのデータのアーカイブ。
- S3 にデータを格納するのに有効なコストは、レプリケーション・ファクタで HDFS と比較して安価です。
- 一時 EMR クラスターを使用し、ジョブが完了した後にクラスターをシャットダウンし、データを S3 に保持する機能。
- スポットインスタンスを使用して、いつでもスポットインスタンスを失うことを心配することができない。
- ノード障害が HDFS のレプリケーション・ファクタを超えた場合に、HDFS ノードの障害からデータの持続性を提供。
- S3 への高スループットデータストリームによるデータ取り込みは、HDFS への取り込みよりもはるかに簡単です。
AWS認定試験の練習問題
- 質問はインターネットから収集され、答えは自分の知識と理解に基づいてマークされます(これはあなたと異なる場合があります)。
- AWSサービスは毎日更新され、回答と質問はすぐに時代遅れになる可能性がありますので、それに応じて調査してください。
- AWSのアップデートのペースを追うためにAWS試験の質問は更新されないため、基礎となる機能が変更されても質問が更新されないことがあります。
- さらなるフィードバック、ディスカッション、修正を可能にします。
- Amazon Elastic Map Reduce を使用して Amazon S3 に格納されている大量のデータを分析する機能が必要です。 cc2.8xlarge インスタンス・タイプを使用しています。このタイプの CPU は処理中にほとんどアイドル状態です。 次のうち、ジョブの実行時間を短縮する最もコスト効率の高い方法はどれですか?[PROFESSIONAL]
- Amazon S3 で小さいファイルを作成します。
- タスクグループを導入して、追加の cc2.8xlarge インスタンスを追加します。
- 集約された I/Oパフォーマンスのより小さいインスタンスを使用します。
- Amazon S3 でより少ない、より大きなファイルを作成します。
- 顧客の夜間の EMR ジョブは、Amazon Simple Storage Service(S3) に格納された単一の 2TB データファイルを処理します。 Amazon Elastic Map Reduce(EMR) ジョブは、2つのオンデマンドコアノードと3つのオンデマンドタスクノードで実行されます。 EMRジ ョブの完了時間を短縮するのに役立つのはどれですか? 2つの回答を選択してください[PROFESSIONAL]
- タスクノードの3つのオンデマンドインスタンスではなく、3つのスポットインスタンスを使用します。
- MapReduce ジョブ構成の入力分割サイズを変更します。
- ブートストラップアクションを使用して、S3 バケットをローカルファイルシステムとして表示します。
- Amazon 仮想クラウド内のコアノードとタスクノードを起動します。
- 同時マッパータスクの数を調整します。
- ジョブフローの終了保護を有効にします。
- 部門では、会社のログファイルから定期的な分析レポートを作成します。 すべてのログデータは Amazon S3 で収集され、Amazon Redshift データウェアハウス用の CSV 形式の日別 PDF レポートと集計テーブルを生成する毎日の Amazon Elastic Map Reduce(EMR) ジョブによって処理されます。 お客様の CFO は、このシステムのコスト構造を最適化することを要求します。 以下の代替案のどれが、システムの平均パフォーマンスや RAW データのデータ保全性を損なうことなくコストを削減できますか? [PROFESSIONAL]
- Amazon S3 の PDF および CSV データには低冗長ストレージ(RRS)を使用します。 スポットインスタンスを Amazon EMR ジョブに追加します。 Amazon Redshift 用の予約済みインスタンスを使用します。(スポットインスタンスのみがパフォーマンスに影響します)
- S3 のすべてのデータに対して、低冗長ストレージ (RRS) を使用します。Amazon EMR ジョブのスポットインスタンスとリザーブドインスタンスの組み合わせを使用します。Amazon Redshift にリザーブドインスタンスを使用する (スポットと予約を組み合わせてパフォーマンスを保証し、コストを削減します。また、RRSはコストを削減し、データの耐久性とは異なるデータの完全性を保証します)
- Amazon S3 のすべてのデータに対して、低冗長ストレージ (RRS) を使用します。Amazon EMR ジョブにスポットインスタンスを追加します。Amazon Redshift にリザーブドインスタンスを使用する (スポットインスタンスのみがパフォーマンスに影響を与える)
- S3 の PDF および CSV データに対して、低冗長ストレージ (RRS) を使用します。EMR ジョブにスポットインスタンスを追加します。Amazon Redshift にスポットインスタンスを使用します。(スポットインスタンスはパフォーマンスに影響し、スポットインスタンスは Redshift では使用できません)
- 研究科学者は、Elastic MapReduce クラスターの一度目の立ち上げを計画しており、マネージャーがコストを最小限に抑えることを奨励しています。 このクラスタは 200TB のゲノミクスデータを合計100個の Amazon EC2 インスタンスで処理するように設計されており、約4時間稼働する予定です。 結果のデータセットは、Amazon RDS Oracleインスタンスにアーカイブされるまで一時的に保存する必要があります。 どのオプションが、要件を満たしながら最大の費用を節約するのに役立ちますか?[PROFESSIONAL]
- 取り込みと出力ファイルを Amazon S3 に保存します。マスターおよびコアノードのオンデマンドを展開し、タスクノードのスポットを配置します。
- マスター、コア、およびタスクの各ノードに対して、オンデマンド、RI、スポット価格モデルの組み合わせを展開することによって最適化します。アマゾンの Glacier にそれらをアーカイブするライフサイクルポリシーと Amazon S3 で取り込みと出力ファイルを格納します。(マスターとコアは RI またはオンデマンドでなければなりません。スポットにはできません)
- 取り込みファイルを Amazon s3 RRS に保存し、出力ファイルを S3 に保存します。マスターおよびコアノードのリザーブドインスタンスと、タスクノードのオンデマンドを展開します。(取り込みファイルの耐久性が必要です。スポットインスタンスは、コスト削減のためにタスクノードに使用できます。RI は、この場合にはコスト削減を提供しません)
- オンデマンドマスター、コアおよびタスクノードを展開し、Amazon s3 RRS での取り込みと出力ファイルの格納 (入力は S3 標準で行う必要があり、入力データを再取り込みすると、標準の S3 で限られた時間のデータを保持してしまう可能性が高くなります)
- あなたの会社はコンシューマデバイスを販売し、販売されたすべてのデバイスの最初のアクティベーションを記録する必要があります。 情報が永続データベースに書き込まれるまで、デバイスはアクティブ化されません。 アクティベーションデータは貴社にとって非常に重要であり、毎日 MapReduce ジョブで分析する必要があります。 データ分析プロセスの実行時間は、1日当たり3時間未満でなければなりません。 デバイスは通常年間で均等に販売されていますが、新しいデバイスモデルがリリースされている場合は、数日間、平均日数の 10 倍または 100 倍のアクティブ化が予測されます。 このワークロードのコストとパフォーマンスをより適切に最適化するために実装するデータベースと分析フレームワークはどれですか?[PROFESSIONAL]
- Amazon RDS および Amazon の Elastic MapReduce にスポットインスタンスを使用します。
- Amazon DynamoDB および Amazon Elastic MapReduce にスポットインスタンスを使用します。
- Amazon RDS および Amazon Elastic MapReduce にリザーブドインスタンスがあります。
- リザーブドインスタンスを持つ Amazon DynamoDB および Amazon Elastic MapReduce
リファレンス

- AWS Black Belt Online Seminar 2016 Amazon EMR (SlideShare / オンデマンドセミナー)

Jayendra’s Blog
この記事は自己学習用に「AWS Elastic Map Reduce – EMR – Certification(Jayendra’s Blogより)」を日本語に訳した記事です。