
AWS CloudWatch
- Aws CloudWatch は、AWS のリソースとアプリケーションをリアルタイムで監視します。
- CloudWatch を使用すると、リソースやアプリケーションに対して測定される変数であるメトリックを収集および追跡できます。
- CloudWatch アラームを設定可能
- 通知を送信
- 定義されたルールに基づいてリソースを自動的に変更する
- AWS に付属する組み込みのメトリックスを監視するだけでなく、カスタムメトリックスを監視することもできます。
- CloudWatch は、リソース使用率、アプリケーションパフォーマンス、および運用状態をシステム全体で可視化します。
- 既定では、CloudWatch はログデータを無期限に保存し、ロググループごとに保存期間を変更できます。
- CloudWatch アラーム履歴はわずか14日間保存されます
- SysOps Associate&DevOps Professional 試験の主に必須
CloudWatch アーキテクチャ
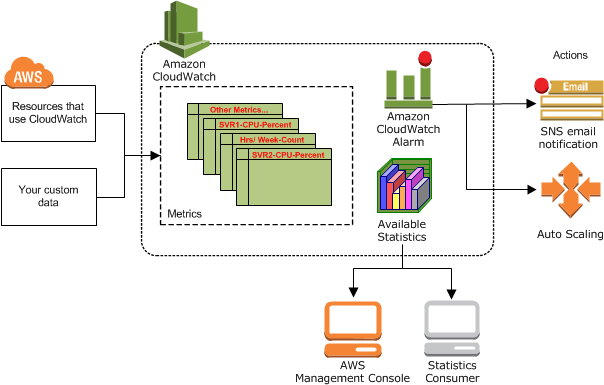
- CloudWatch は様々なリソースから様々な指標を収集
- これらのメトリックスは、統計として、コンソール、CLI を使用してユーザーが利用できます。
- CloudWatch は定義された規則の警報の作成を可能にする
- インスタンスの自動スケーリングまたは停止、開始、または終了のアクションを実行する
- あなたに代わって SNS アクションを使用して通知を送信する
CloudWatch の概念
メトリック
- メトリックは、CloudWatch の基本的な概念です。
- 名前、名前空間、および1つ以上のディメンションによって一意に定義されます。
- CloudWatch にパブリッシュされたデータポイントの時間順序付きセットを表します。
- 各データポイントにはタイムスタンプがあり、(オプションで) 測定単位があります。
- データポイントは、カスタムメトリックまたは AWS の他のサービスのメトリックのいずれかになります。
- 統計情報は、指定されたタイム・ウィンドウ内で発生する時系列データの順序付きセットとして、これらのデータ・ポイントについて取得できます。
- 統計情報が要求されると、返されるデータストリームは、名前空間、メトリック名、ディメンション、および (オプションで) 単位によって識別されます。
- メトリックスは、作成されたリージョンにのみ存在します。
- CloudWatch は2週間のメトリックデータを格納します。
- メトリックスは削除できませんが、新しいデータが公開されていない場合は、14日以内に自動的に失効します。
- **注:2016年11月 AWS では、拡張メトリック保持を提供します
- 1分間のデータポイントは15日間ご利用いただけます。
- 5分間のデータポイントは63日間ご利用いただけます。
- 1時間のデータポイントは455日 (15 か月) の間利用できる。
名前空間
- CloudWatch 名前空間はメトリックのコンテナです。
- 異なる名前空間のメトリックスは互いに分離されるため、異なるアプリケーションのメトリックスが同じ統計に誤って集約されることはありません。
- AWS/EC2 や AWS/ELB などについては、すべての名前空間が AWS/<サービス> に従います。
- 名前空間の名前は、長さが256文字未満である必要があります。
- 既定の名前空間はありません。CloudWatch に入れる各データ要素は、名前空間を指定する必要があります。
ディメンション
- ディメンションは、メトリックを一意に識別する名前と値のペアです。
- すべてのメトリックスには、それを記述する特定の特性があり、これらの特性のカテゴリとしてディメンションを考えることができます。
- ディメンションは、統計計画の構造を設計するのに役立ちます。
- ディメンションはメトリックの一意の識別子の一部であり、メトリックのいずれかに一意の名前ペアが追加されるたびに、新しいメトリックが作成されます。
- ディメンションを使用して、CloudWatch クエリが返す結果セットをフィルター処理できます。
- メトリックには、最大10個のディメンションをメトリックに割り当てることができます。
タイムスタンプ
- 時系列上のデータポイントを識別するには、各メトリックデータポイントにタイムスタンプを付けてマークする必要があります。
- タイムスタンプは、過去2週間、最大2時間の将来にすることができます。
- タイムスタンプが指定されていない場合、CloudWatch はデータ要素が受信された時刻に基づいてタイムスタンプを作成します。
- 統計情報が取得されると、すべての時間は UTC タイムゾーンを反映します。
単位
- 単位は数、バイト、% 等のための測定の統計量の単位を表す
統計
- 統計は、指定した期間におけるメトリックデータ集計です。
- 集計は、指定した期間内に、名前空間、メトリック名、ディメンション、およびデータポイント単位を使用して作成されます。
期間
- 期間は、特定の統計に関連付けられた時間の長さです。
- 各統計は、指定した期間に収集されたメトリックデータの集計を表します。
- ピリオドは秒単位で表されますが、期間の最小粒度は1分です。
集計
- CloudWatch は、GetMetricStatistics の呼び出しで指定された期間の長さに従って統計を集計します。
- 複数のデータポイントは、同じまたは類似のタイムスタンプでパブリッシュできます。CloudWatch は、それらのデータポイントに関する統計情報が要求されたときに、それらを期間の長さで集計します。
- 集計された統計情報は、詳細な監視を使用する場合にのみ使用できます。
- 基本監視を使用するインスタンスは、集計に含まれません。
- CloudWatch は、リージョン間でデータを集計しません。
アラーム
- アラームは、指定されたパラメータに基づいて、ユーザーに代わって自動的にアクションを開始できます。
- アラームは、指定された期間にわたって1つのメトリックを監視し、一定の期間にわたって特定のしきい値を基準としたメトリックの数値に基づいて1つ以上のアクションを実行します。
- アラームは、状態が変更されている必要があり、指定した期間の維持されている状態の持続的な変更のためのアクションを呼び出します
- アクションができること
- SNS 通知
- 自動スケーリングポリシー
- EC2 アクション – EC2 インスタンスの停止または終了
- 状態の変更によってアラームがアクションを起動すると、その後の動作はアラームに関連付けられたアクションの種類によって異なります。
- 自動スケーリングポリシー通知の場合、アラームは、アラームが新しい状態のままであるすべての期間に対してアクションを呼び出し続けます。
- SNS 通知の場合、追加のアクションは呼び出されません。
- アラームには3つの状態があります。
- OK: メトリックは定義されたしきい値内にあります。
- ALARM: メトリックが定義されたしきい値を超えています。
- INSUFFICIENT_DATA: アラームが開始されたばかりのため、メトリックスが利用できないか、またはメトリックスがアラーム状態を判断するのに十分なデータが利用できない
- アラームは、作成されたリージョンにのみ存在します。
- アラームアクションは、アラームと同じリージョンに存在する必要があります
- 過去14日間のアラーム履歴を利用できます。
- アラームは、SetAlarmState API (mon-alarm-state コマンド) を使用して任意の状態に設定することによってテストすることができます。この一時的な状態の変更は、次のアラームの比較が行われるまで続きます。
- DisableAlarmActions および EnableAlarmActions API を使用してアラームを無効にして有効にすることができます (mon-disable-alarm-actions および mon-enable-alarm-actions コマンド)。
リージョン
- CloudWatch はリージョン間でデータを集計しません。したがって、メトリックはリージョン間で完全に分離されています。
カスタムメトリック
- CloudWatch は、put-metric-data CLI コマンド (またはそのクエリ API 相当 PutMetricData) を使用してカスタムメトリックスを公開できます。
- CloudWatch は、新しいメトリックの名前で PUT メトリックデータが呼び出された場合に新しいメトリックを作成し、それ以外の場合は、指定した既存のメトリックにデータを関連付けます。
- put-metric-data コマンドは、呼び出しごとに1つのデータポイントのみを公開できます。
- CloudWatch は、データポイントの系列としてメトリックに関するデータを格納し、各データポイントに関連付けられたタイムスタンプ
- put-metric-data コマンドを使用して新しいメトリックを作成するには、統計情報を取得するまでに最大2分かかることがあり、メトリック統計コマンドを使用して新しいメトリックを取得し、新しいメトリックがメトリックの一覧に表示されるまでに最大15分かかることがあります list-metrics コマンドを使用して取得します。
- CloudWatch は発行を許可する
- 単一データポイント
- データポイントは、1秒の 1/1000 として粒状としてタイムスタンプで公開することができ、CloudWatch は、データを最小の粒度に集約します。
- CloudWatch は、1分間に受信した値の平均 (項目数で割ったすべての項目の合計)、サンプル数、最大値、および同じ期間の最小値を記録します。
- CloudWatch は、データポイントを集計するときに1分間の境界を使用します。
- 統計セットと呼ばれるデータポイントの集合
- データは、CloudWatch に公開される前に集計することもできます。
- データを集約することで、コールの数を最小限に抑え、データの統計セットを使用して1分間に1回のコールに減らします。
- 統計には、合計、平均、最小、最大、データサンプルが含まれます。
- 単一データポイント
- アプリケーションがより散発的で、データが関連付けられていない期間を持つデータを生成する場合は、値ゼロ (0) またはまったく値を発行できません。
- ただし、値なしではなくゼロを発行すると便利です。
- たとえば、アラームが5分ごとに公開されていないかどうかを通知するようにアプリケーションの状態を監視するには
- データポイントの合計数を追跡する
- 値 0 のデータポイントを含めるために、最小および平均などの統計情報を持つこと。
- ただし、値なしではなくゼロを発行すると便利です。
サポートされるサービス
- サポートされるサービス (参照:CloudWatch Supported Services)
CloudWatchへのアクセス
- CloudWatch へアクセスすることができます
- AWS CloudWatchコンソール
- CloudWatch CLI
- AWS CLI
- CloudWatch API
- AWS SDK
AWS認定試験の練習問題
- 質問はインターネットから収集され、答えは自分の知識と理解に基づいてマークされます(これはあなたと異なる場合があります)。
- AWSサービスは毎日更新され、回答と質問はすぐに時代遅れになる可能性がありますので、それに応じて調査してください。
- AWSのアップデートのペースを追うためにAWS試験の質問は更新されないため、基礎となる機能が変更されても質問が更新されないことがあります。
- さらなるフィードバック、ディスカッション、修正を可能にします。
- 企業は、AWS MySQL RDS インスタンスの読み取りおよび書き込みの IOPs メトリックを監視し、リアルタイムのアラートを運用チームに送信する必要があります。これはどの AWS サービスで実現できますか?2つの回答を選択
- Amazon Simple Email Service (直接 CloudWatch と統合することはできません)
- Amazon CloudWatch
- Amazon Simple Queue Service
- Amazon Route 53
- Amazon Simple Notification Service
- 顧客は、5分ごとにロードバランサーからすべてのクライアント接続情報を取得する必要があります。同社は、トラフィックのパターンを分析し、そのアプリケーションのトラブルシューティングにこのデータを使用したい。お客様の要件を満たすオプションは次のどれですか。
- ロードバランサーに対して AWS CloudTrail を有効にします。
- ロードバランサーのアクセスログを有効にします。(リンク参照)
- ロードバランサーに Amazon CloudWatch ログエージェントをインストールします。
- ロードバランサーで Amazon CloudWatch メトリックを有効にする (クライアント接続情報を提供しません)
- ユーザーは、EBS でバックアップされた EC2 インスタンスでバッチプロセスを実行しています。 バッチ処理では、Hadoop Map reduce ジョブを処理するためにいくつかのインスタンスが開始されます。ジョブは50〜600分または時にはさらに時間がかかります。 ユーザーは、プロセスが完了したときにのみインスタンスが終了するように構成する必要があります。 ユーザーはCloudWatchでこれをどのように設定できますか?
- CPU 使用率が 5% 未満の場合にインスタンスを終了するように CloudWatch アクションをセットアップします。
- 自動スケーリングを使用して CloudWatch をセットアップし、すべてのインスタンスを終了する
- 600分後にすべてのインスタンスを終了するジョブをセットアップする
- インスタンスを自動的に終了することはできません。
- ユーザーには2つの別個の領域で実行される2つの EC2 インスタンスがあります。ユーザーは、同じ名前空間とメトリックを持つ CLI を使用して、データをキャプチャし、米国東部の CloudWatch に送信する内部メモリ管理ツールを実行しています。上記のステートメントに関して、以下のオプションのうちどれが該当しますか?
- CloudWatch がリージョン間でデータを受信できないため、セットアップは機能しません。
- CloudWatch は、名前空間とメトリックに基づいてデータを受け取り、集計します。
- CloudWatch は、データが2つのソースのために競合するため、エラーを与える
- CloudWatch は、最初にデータを送信するサーバーのデータを取得します
- ユーザーが CloudWatch API を使用して CloudWatch にデータを送信しています。ユーザーは、今後データを90分間送信しています。この場合、CloudWatch は何を行いますか?
- CloudWatch は、データを受け入れる
- 将来のデータを送信することはできません。
- CloudWatch にデータを手動で送信することはできません。
- ユーザーは、今後60分以上のデータを送信することはできません。
- ユーザーは、特定のイベントに基づいてランダムに生成されたデータを持っています。ユーザーは、そのデータを CloudWatch にアップロードする必要があります。イベントによっては、乱数のためにデータが生成されない場合があります。この場合の推奨オプションは以下のとおりです。
- データがない期間については、ユーザーはデータをまったく送信しないでください。
- データがない期間については、ユーザーは空白の値を送信する必要があります
- データがない期間は、ユーザーが 0 として値を送信する必要があります (ユーザーガイドを参照)
- ユーザーは、ある期間のデータがないとして CloudWatch にデータをアップロードする必要があります CloudWatch 監視でエラーが発生します。
- ユーザーは、計量プラントを持っています。ユーザーは、5分ごとにいくつかの商品の重量を測定し、監視と追跡のために AWS CloudWatch にデータを送信します。ユーザーが要求リストに含めるためには、以下のパラメータのうちどれが必須ですか。
- 値
- 名前空間 (put-metric リクエスト を参照)
- メトリック名
- タイムゾーン
- ユーザーは、冷蔵庫の工場を持っています。ユーザーは、15分ごとに植物の温度を測定している。ユーザーがデータを視覚的に表示するためにデータを CloudWatch に送信したい場合は、上記の情報に関して以下の記述のうちどれが真であるか。
- ユーザーは、データをアップロードするために AWS CLI または API を使用する必要があります。
- ユーザーは AWS インポートエクスポート機能を使用して、CloudWatch にデータをインポートできます。
- ユーザーは AWS コンソールからデータをアップロードします。
- ユーザーは AWS サービスメトリックではないため、CloudWatch にデータをアップロードできません
- ユーザーが EC2 インスタンスを起動しました。ユーザーは CloudWatch アラームのセットアップを計画しています。CloudWatch アラームでサポートされていないアクションは、以下のうちどれですか?
- スケールアップの自動スケーリング起動設定を通知する
- SNS を使って SMS を送る
- 自動スケーリンググループにスケールダウンを通知する
- EC2 インスタンスを停止する
- ユーザーは、最後の1週間のすべての CloudWatch メトリックデータを集約しようとしています。以下のうち、データ集計の一部としてユーザーに利用できない統計はどれですか?
- 集計
- 合計
- サンプルデータ
- 平均
- ユーザーは、CPU 使用率が 75% を超えると、EC2 アクションに CloudWatch アラームを設定します。アラームは、アラーム状態の SNS に通知を送信します。ユーザーがアラームアクションをシミュレートしたい場合は、どのように彼はこれを達成することができます?
- CPU 上でアクティビティを実行し、その使用率が 75% 以上に達するようにします。
- AWS コンソールから状態を「アラーム」に変更します。
- ユーザは、CLI を使用してアラーム状態を「アラーム」に設定できます。
- SNS アクションを手動で実行する
- ユーザーが CloudWatch にカスタムメトリックスを公開しています。以下のステートメントのどれが、ユーザーが機能をよりよく理解するのに役立ちますか。
- ユーザーは CloudWatch インポートツールを使用できます。
- ユーザーは、約15分後にコンソールでデータを見ることができるはずです
- ユーザーがカスタムデータをアップロードする場合、ユーザーはコマンドの一部として名前空間、タイムゾーン、およびメトリック名を指定する必要があります。
- ユーザーは、コンソール、CLI、API を使用してデータをアップロードするだけでなく、表示することもできます。
- 管理するアプリケーションには、複数の AWS リージョンにデプロイされた EC2 インスタンスと DynamoDB テーブルがあります。アプリケーションのパフォーマンスをグローバルに監視するために、すべての EC2 インスタンスでの平均 CPU 使用率と 2) すべての DynamoDB テーブルのスロットル要求数を2つのグラフで確認します。どのようにこれを達成することができますか?[PROFESSIONAL]
- アプリケーション名を使用してリソースにタグを付け、CloudWatch 管理コンソールのディメンションとしてタグ名を選択して、それぞれのグラフを表示します (CloudWatch メトリックはリージョン)。
- CloudWatch CLI ツールを使用して、各リージョンのエンドポイントからそれぞれのメトリックを引き出します。データをオフラインで集計し、CloudWatch のグラフに保存します。
- 各インスタンスおよび DynamoDB テーブルに SNMP トラップを追加します。中央監視サーバーを活用して、各インスタンスとテーブルからデータをキャプチャします。グラフの CloudWatch に集計データを配置する (管理されたサービスであるため、DynamoDB に SNMP トラップを追加することはできません)
- 各インスタンスに CloudWatch エージェントを追加し、各 DynamoDB テーブルに1つをアタッチします。エージェントを設定するときは、適切なアプリケーション名と CloudWatch のグラフを表示します。(管理されたサービスとして DynamoDB にエージェントを追加することはできません)
- 各プロジェクトに対して個別の AWS アカウントを設定しました。AWS インフラストラクチャのコストが毎月のプロジェクトごとの予算セットを超えないようにするように求められています。毎月予算を超過しないようにするには、次のどちらの方法が役立ちますか。[PROFESSIONAL]
- すべてのアカウントとプロジェクトに対して1つの請求書を持っているので、アカウントを統合します (連結はアカウントごとの制限には役立ちません)
- SNS を使用した CloudWatch アラームによる自動スケーリングの設定特定のアカウントで多数のインスタンスを実行している場合に通知する (多くのインスタンスはコストに直接マップせず、正確なコストを与えることはありません)
- 各プロジェクトで使用されているすべての AWS リソースに対して CloudWatch 請求アラートを設定し、特定のプロジェクトにタグ付けした各リソースの金額がプロジェクトに割り当てられた予算と一致する場合に通知が発生します。(各プロジェクトには既にアカウントがあるため、リソースのタグ付けは必要ありません)
- 各アカウントで使用されているすべての AWS リソースに対して CloudWatch 課金アラートを設定し、50% に達したときに電子メールで通知します。予算月間費用の 80% と 90%
- 今月のデータを確認するために、運用チームと毎月1回会う。会議中に、3週間前に、AWS の外部から HTTP 経由で ping を実行する監視システムが、3層 web サービス API の待ち時間に大きなスパイクを記録したことに気付きました。DynamoDB は、ビジネスロジック層に対してデータベース層、ELB、EBS、および EC2 に対して使用し、プレゼンテーション層には SQS、ELB、および EC2 を使います。次の方法のうち、何が起こったかを把握するのに役立ちますか?
- 遅延の原因となった API 呼び出しについては、スパイクの時間を中心に CloudTrail ログ履歴を確認してください。
- CloudWatch メトリックグラフを確認して、どのコンポーネントがシステムを減速したかを確認します。(メトリックデータは2週間前に利用できましたが、今は拡張されています)
- S3 の ELB アクセスログを確認して、システム内の ELB が待ち時間を見たかどうかを確認します。
- ログを分析して、その時点でのトラフィックのバーストを検出します。
- AWS アカウントには高いセキュリティ要件があります。アカウントへの AWS API 呼び出しへの反応に使用できる、最も迅速で洗練されたセットアップとは何ですか。
- SNS トピックを介して AWS 設定へのサブスクリプション。Lambda 関数を使用して、飛行中の解析とその変化に対する反応性を実行します。
- グローバル AWS CloudTrail は、配信通知への SNS サブスクリプションを使用して S3 に配信し、Lambda にプッシュして、分析のために ELK スタックにレコードを挿入するセットアップを行います。
- CloudWatch ルール ScheduleExpression を使用して、IAM 資格情報ログを定期的に分析します。イベントのデルタを ELK スタックにプッシュし、そこでアドホック分析を実行します。
- CloudWatch イベントルールは、すべての AWS API 呼び出しに基づいてトリガされ、すべてのイベントを AWS Kinesis Streams に送信して、任意のダウンストリーム解析を行います。 (CloudWatch イベントは、AWS API 呼び出しへのサブスクリプションと、これらのイベントの方向を Kinesis Streams に許可します。これにより、すべての API 呼び出しについて、ほぼリアルタイムの統一されたストリームを、どのツールでも分析できるようになります。リンク参照)
- 異なるユーザーとエンティティによる AWS アカウントに対する API 呼び出しを監視するには、____ を使用して、後で確認するために一括して呼び出し履歴を作成し、____ を使用してリアルタイムで AWS API 呼び出しに反応することができます。
- AWS Config ; AWS Inspector
- AWS CloudTrail ; AWS Config
- AWS CloudTrail ; CloudWatch イベント(CloudTrail はバッチ API 呼び出しコレクションサービスであり、CloudWatch イベントは、Rules オブジェクトインターフェイスを通じた呼び出しのリアルタイム監視を可能にします。リンク参照)
- AWS 設定;AWS Lambda
- あなたは SaaS の会社のための操作の新しいヘッドとして雇われている。あなたの CTO は、あなたの全体の操作の任意の部分を簡単に、できるだけ早くデバッグするように求めている。彼女は、複雑なサービス指向のアーキテクチャでは、開発者がディスクにログオンするだけで、非常に多くのサービスでログのエラーを見つけるのは難しいので、何が起こっているのか見当がつかないという不満を抱いています。この要件を満たし、CTO を満足させるにはどうすればよいでしょうか。[PROFESSIONAL]
- 各インスタンスの cron ジョブを使用して、すべてのログファイルを AWS S3 にコピーします。
PutBucketイベントで S3 通知構成を使用し、AWS Lambda にイベントをパブリッシュします。Lambda を使用して、問題が発生したときにすぐにログを分析します。(検索では高速ではありませんし、遅延を生じる) - すべてのサービスで CloudWatch ログの使用を開始します。すべてのロググループを S3 オブジェクトにストリーミングします。AWS EMR クラスタジョブを使用して、アドホック MapReduce 分析を実行し、必要に応じて新しいクエリを作成します。(検索では高速ではありませんし、遅延を生じる)
- 各インスタンスの cron ジョブを使用して、すべてのログファイルを AWS S3 にコピーします。
PutBucketイベントで S3 通知構成を使用し、AWS Kinesis にイベントをパブリッシュします。AWS EMR で Apache Spark を使用して、ログチャンクおよびフラグの問題に対して、スケールストリーム処理クエリを実行します。(検索では高速ではありませんし、遅延を生じる) - すべてのサービスで CloudWatch ログの使用を開始します。すべてのロググループを KIBANA 4 を実行している AWS Elasticsearch サービスドメインにストリーミングし、検索クラスタでログ分析を実行します。(ELK – Elasticsearch、Kibana スタックは、リアルタイムのアドホックログ分析と集約のために特別に設計されています)
- 各インスタンスの cron ジョブを使用して、すべてのログファイルを AWS S3 にコピーします。
- EC2 ベースのマルチティアアプリケーションには、さまざまなアプリケーションコンポーネントのアプリケーションレベルの読み取り専用要求を定期的に作成する監視インスタンスが含まれています。これらのコンポーネントのいずれかが30秒以上失敗すると、CloudWatch がアラームを発生させ、 電子メールと SMS を使用して、アプリケーションの健全性の問題を検討してください。 ただし、ウォッチャー(監視インスタンス自体)を監視し、不健全になった場合は通知を受ける必要があります。 次のうち、その目標を達成するための簡単な方法はどれですか?[PROFESSIONAL]
- 監視インスタンスを ping する別の監視インスタンスを実行し、アラームマットを起動すると、プライマリ監視インスタンスが異常になるようにオペレーションチームに通知します。
- EC2 システムおよびインスタンスステータスチェックに基づいて CloudWatch アラームを設定し、監視インスタンスで検出された問題のオペレーションチームにアラームを通知します。
- 監視インスタンスの CPU 使用率に基づいて CloudWatch アラームを設定し、CPU 使用率が 50% を超えて 1 分を超える場合はアラームを運用チームに通知します。監視アプリケーションを CPU バインドループに移行させる アプリケーションの問題を検出します。
- 監視インスタンスが SOS キューにメッセージをポストしてからキューが新しいメッセージを停止すると、別のインスタンスのメッセージをデキューし、2番目のインスタンスは最初に元の監視インスタンスを終了し、別のバックアップ監視インスタンスを開始し、 インスタンスを監視し、SQSキューにメッセージを追加し始めます。
リファレンス
- Black Belt Online Seminar Amazon CloudWatch (SlideShare / オンデマンドセミナー)

Jayendra’s Blog
この記事は自己学習用に「AWS CloudWatch – Certification(Jayendra’s Blogより)」を日本語に訳した記事です。