

Jayendra’s Blog
この記事は自己学習用に「AWS Auto Scaling – Certification(Jayendra’s Blogより)」を日本語に訳した記事です。
Auto Scaling 概要
- Auto Scaling は、アプリケーションの負荷を処理するために常に正しい数の EC2 インスタンスが実行されていることを保証する機能を提供します。
- Auto Scaling は、より良い耐障害性、より良い可用性、およびコスト管理を実現するのに役立ちます。
- Auto Scaling はまた、EC2 インスタンスを起動および終了してアプリケーションの需要の増加または減少を処理するために使用できるスケーリングポリシーを指定するのに役立ちます。
- Auto Scaling は、オートスケーリンググループで有効になっている AZ 間でインスタンスを均等に分散しようとします。
- Auto Scaling は、最小のインスタンスで AZ に新しいインスタンスを起動しようと試みることによってこれを行います。 試行が失敗すると、オートスケーリングは別の可用性ゾーン内のインスタンスを正常に起動するまで起動します。
Auto Scaling 構成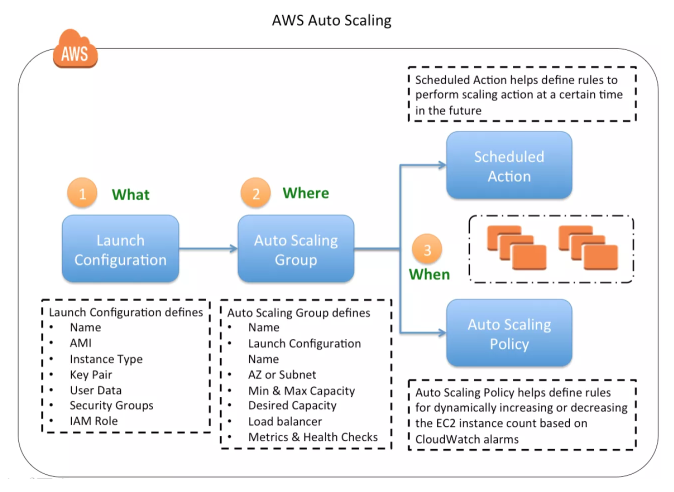

起動設定
- 起動設定は、Auto Scaling グループが EC2 インスタンスを起動するために使用するテンプレートです。
- 起動構成は、EC2 構成に似ており、Amazon マシンイメージ (AMI)、インスタンスタイプ、キーペア、1つ以上のセキュリティグループ、およびブロックデバイスマッピングの選択が含まれます。
- 起動設定は複数の Auto Scaling グループに関連付けられます。
- 作成後に起動構成を変更することはできず、変更が必要な場合は新規に作成する必要がある。
- Auto Scaling グループ内のインスタンスの基本または詳細な監視は、起動構成の作成時に有効にできます。
- デフォルトでは、AWS マネジメントコンソールを使用して起動設定を作成し、AWS CLI または API を使用して起動設定を作成するときに詳細な監視を有効にすると、基本監視が有効になります。
Auto Scaling グループ
- Auto Scaling グループは Auto Scaling の中核であり、類似した特性を共有し、インスタンスのスケーリングと管理を目的として論理グループとして扱われる EC2 インスタンスのコレクションを含んでいます。
- Auto Scaling グループ要件
- 起動設定して、インスタンスの起動に使用する EC2 テンプレートを決定する。
- Auto Scaling ポリシーが適用された場合のインスタンス数を決定する 最小および最大キャパシティ。 インスタンスの数はこの境界を超えて拡大することはできません
- 希望する容量
- ASG が常に維持しなければならないインスタンスの数を決定します。行方不明の場合は、最小サイズに等しくなります。
- 必要な容量と、最小容量とは異なります。
- Auto Scaling グループの望ましい容量は、実行すべきデフォルトのインスタンス数です。グループの最小容量は、グループが実行可能なインスタンスの最小数です。
- インスタンスが起動される アベイラビリティーゾーンまたはサブネット
- メトリックスとヘルスチェック – インスタンスを起動または終了するタイミングを決定するメトリックと、インスタンスが正常であるかどうかを判断するためのヘルスチェック。
- Auto Scaling グループは、インスタンスの望ましい容量を起動して開始し、定期的なヘルスチェックを実行してこの数を維持します。
- インスタンスが不健全になると、インスタンスは終了し、新しいインスタンスを起動します。
- Auto Scaling グループはスケーリングポリシーを使用して、変化する要求を満たすためにインスタンスの数を自動的に増減できます。
- Auto Scaling グループには、同じリージョン内の1つ以上の AZ に EC2 インスタンスを含めることができます。
- Auto Scaling グループは、複数のリージョンにまたがることはできません。
- 別々のsingle-zone.Auto Scaling グループを複数の AZ にまたがる単一の Auto Scaling グループにマージするには、シングルゾーングループの1つをマルチゾーングループにリゾーンしてから、他のグループを削除します。 このプロセスは、新しいマルチゾーングループが元のシングルゾーングループと同じ AZ のいずれかにあるかぎり、ロードバランサの有無にかかわらず、グループに適用されます。
- Auto Scaling グループは、単一の起動設定に関連付けることができます。
- 起動設定を作成した後は変更できないため、Auto Scaling グループの 起動設定を更新する方法は、新しいスケーリンググループを作成し、それを Auto Scaling グループに関連付けることだけです。
- Auto Scaling グループの起動設定が変更されると、新しいインスタンスが起動されたときに新しい設定パラメータが使用されますが、既存のインスタンスは影響を受けません。
- Auto Scaling グループは実行中のインスタンスがない場合は CLI から削除できます。その他の場合は最小限の容量を0に設定する必要があります。これは、AWG 管理コンソールから ASG を削除すると自動的に処理されます。
AUto Scaling プラン
インスタンスの定常数の管理
- Auto Scaling では、インスタンスの安定した最小値(または指定が必要な場合)が常に実行されます。
- インスタンスが正常でないと判明した場合、Auto Scaling はインスタンスを終了して新しいインスタンスを起動します。
- Auto Scaling グループは、EC2 インスタンスステータスチェックの結果を定期的にチェックすることによって、各インスタンスの正常性状態を判断します。
- Auto Scaling グループは、Elastic Load Balancing ヘルスチェックを使用できるロードバランサに関連付けられ、Auto Scaling は、EC2 インスタンスステータスと Elastic Load Balancing インスタンスヘルスの両方の結果をチェックして、インスタンスの正常性ステータスを判断します。
- Auto Scaling によってインスタンスが異常にマークされ、置き換えが開始された場合
- インスタンスは実行中以外の状態にあります
- システムステータスが損なわれているか、または
- ELB は、インスタンスの状態を OutOfService として報告します。
- インスタンスが EC2 または ELB ヘルスチェックの結果として異常とマークされた後は、ほぼすぐに交換が予定されています。それは自動的に Healthy に回復することはありません。
- 不健全なインスタンスの場合、インスタンスのヘルスチェックは手動で正常に戻すことができますが、インスタンスがすでに終了している場合はエラーが発生します。 不健全なインスタンスとその実際の終了をマークする間隔が非常に小さいため、インスタンスの正常性状態を元に戻すことを試みるのは、中断されたグループに対してのみ有効です。
- インスタンスが終了すると、関連付けられている Elastic IP アドレスは解除され、新しいインスタンスに自動的に関連付けられることはありません。
- Elastic IP アドレスは、新しいインスタンスに手動で関連付ける必要があります。
- 同様に、インスタンスが終了すると、アタッチされた EBS ボリュームはデタッチされ、新しいインスタンスに手動でアタッチする必要があります。
Manual Scaling
- Manual Scaling を実行するには、
- Auto Scaling グループの 必要な容量制限を変更する。
- Auto Scaling グループへのインスタンスのアタッチ/デタッチ。
- EC2 インスタンスのアタッチ/デタッチを実行するには、
- インスタンスは実行中です。
- インスタンスを起動するために使用された AMI は引き続き存在する必要があります。
- インスタンスは別の Auto Scaling グループのメンバーではありません。
- インスタンスは、Auto Scaling グループと同じ Availability Zone にあります。
- Auto Scaling グループがロードバランサに関連付けられている場合、インスタンスとロードバランサは両方とも同じ VPC 内になければなりません。
- Auto Scaling は、接続されているインスタンスの数だけ、グループの望ましい容量を増やします。しかし、接続されているインスタンスの数に必要な容量を加えた数に、グループの最大サイズを超えると、要求は失敗します。
- インスタンスをデタッチする場合、Auto Scaling グループの希望する容量をデタッチするインスタンスの数だけ減らすことができます。容量を減らさないことを選択した場合、Auto Scaling は新しいインスタンスを起動して、切断したインスタンスを置き換えます。
- ロードバランサにも登録されている Auto Scaling グループからインスタンスをデタッチすると、そのインスタンスはロードバランサから登録解除されます。ロードバランサの接続が切断されている場合、Auto Scaling は実行中のリクエストが完了するまで待機します。
スケジュールされたスケーリング
- スケジュールに基づいてスケーリングすることで、予測可能な負荷の変化に応じてアプリケーションを拡張できます。 月の最終日、会計年度の最終日。
- スケジュールされたスケーリングでは、スケジュールされたアクションの構成が必要であり、スケーリングアクションを有効にする開始時刻と、グループに必要な新しい最小値、最大値、および必要サイズを指定して、将来、特定の時間にスケーリングアクションを実行するように Auto Scaling に指示します。
- Auto Scaling は、同じグループ内のスケジュールされたアクションの実行順序を保証しますが、グループ間のスケジュールされたアクションの実行順序は保証しません。
- 複数のスケジュールされたアクションを指定できますが、一意の時刻値を持つ必要があり、重複した時間をスケジュールできないため、拒否されます。
Dynamic Scaling
- たとえば、インスタンスの CPU 使用率が 70% を超え、CPU 使用率が 30% を下回る場合にスケールアウトするなど、変更された需要に応じて自動的にスケーリングすることができます。
- Auto Scaling グループでは、アラームとポリシーの組み合わせを使用して、スケーリングの条件を満たすタイミングを決定します。
- アラームは、指定した期間にわたって1つのメトリックスを監視するオブジェクトです。メトリックスの値が定義されたしきい値に違反した場合、指定された期間の数について、アラームは1つ以上のアクション (Auto Scaling へのメッセージの送信など) を実行します。
- ポリシーは、アラームメッセージに応答する方法を Auto Scaling する命令のセットです。
- Dynamic Scaling プロセスは以下のように動作します。
- Amazon Cloudwatch は、Auto Scaling グループ内のすべてのインスタンスについて、指定されたメトリックを監視します。
- 変更は、需要が拡大または縮小するにつれてメトリックに反映されます。
- メトリックスの変更が Cloudwatch アラームのしきい値に違反すると、Cloudwatch アラームはアクションを実行します。違反に応じて、アクションはスケールインポリシーまたはスケールアウトポリシーに送信されるメッセージです。
- Auto Scaling ポリシーによってメッセージが受信されると、Auto Scaling は Auto Scaling グループのスケーリングアクティビティを実行します。
- この処理は、スケーリングポリシーまたは Auto Scaling グループのいずれかを削除するまで継続されます。
複数のポリシー
- Auto Scaling グループには、特定の時間に複数のスケーリングポリシーを適用することができます。
- 各 Auto Scaling グループには、アーキテクチャをスケールアウトするためのポリシーと、アーキテクチャをスケールするための別の1つがあります。
- AUto Scaling グループに複数のポリシーがある場合、両方のポリシーが同時にスケールアウトまたはスケールアウトするように Auto Scaling スケーリングを指示できる可能性が常にあります。
- このような状況が発生すると、Auto Scaling は、Auto Scaling グループに最も大きな影響を与えるポリシーを選択します。2つのポリシーが同時にトリガされ、ポリシー1がインスタンスを1でスケールアウトするように指示した場合、ポリシー2はインスタンスを2でスケールアウトするように指示しますが、Auto Scaling ではポリシー2を使用し、インスタンスのスケールアウトには大きな影響があります。
Auto Scaling のクールダウン
- Auto Scaling のクールダウン期間は、Auto Scaling グループの構成可能な設定であり、前のスケーリングアクティビティが有効になり、新しく起動されたインスタンスがトラフィックの処理を開始して負荷を軽減する前に、Auto Scaling が追加インスタンスを起動または終了しないようにすることができます。
- Auto Scaling グループは、単純なスケーリングポリシーを使用して動的にスケーリングし、インスタンスを起動すると、スケーリングアクティビティを再開する前に、Auto Scaling によってクールダウン期間 (既定の300秒) のスケーリングアクティビティが中断されます。
- ユースケースの例
- CPU 使用率が増加して 80% になると、スケールアウトアラームを構成して容量を増やします。
- CPU のスパイクが発生し、アラームがトリガーされると、Auto Scaling によって新しいインスタンスが起動します。
- ただし、新しく起動されたインスタンスの設定、インスタンス化、開始には時間がかかりますが、5分と言えます。
- クールダウン期間がない場合、他の CPU スパイクが発生した場合、Auto Scaling は新しいインスタンスを再度起動し、以前に起動したインスタンスが稼働してトラフィックの処理を開始するまで5分間継続します。
- クールダウン期間を使用すると、Auto Scaling により、指定した期間のアクティビティが中断され、新しく起動したインスタンスがトラフィックの処理を開始し、負荷を軽減できるようになります。
- クールダウン期間の後、却時間の後、自動スケーリングが再開してアラームに作用します
- Auto Scaling グループを Manual Scaling する場合、デフォルトではクールダウン期間を待つことはありませんが、デフォルトを上書きしてクールダウン期間を設定することができます。
- インスタンスが異常になると、Auto Scaling では、異常なインスタンスを置き換える前に、クールダウン期間が完了するまで待機しないことに注意してください。
- クールダウン期間は、単純なスケーリングポリシーの動的スケーリングアクティビティに自動的に適用され、ステップスケーリングポリシーではサポートされません。
終了ポリシー
Auto Scaling によって自動的に拡大縮小されるときに、最初にどのインスタンスを終了するかを決定することができます。 Auto Scaling では、既定の終了ポリシーを指定し、カスタマイズしたものを作成することもできます。
規定の終了ポリシー
既定の終了ポリシーは、ネットワークアーキテクチャが AZ に均等にまたがっており、インスタンスが次のように終了するように選択されていることを確認するために設計されています。
- アベイラビリティーゾーンの選択
- 複数の AZ 環境で、ほとんどのインスタンスと、スケールから保護されていない少なくとも1つのインスタンスを使用して AZ を選択します。
- 同じ数のインスタンスを持つ AZ が複数ある場合に、最も古い起動設定を使用するインスタンスで AZ を選択します。
- アベイラビリティーゾーン内のインスタンスの選択
- 古い起動設定 (存在する場合) を使用して、保護されていないインスタンスを終了します。
- 最も古い起動設定を持つ複数のインスタンスがある場合、次の請求時間に最も近い保護されていないインスタンスを終了します。これにより、EC2 インスタンスの使用を最大化し、EC2 の使用量に対して請求される時間数を最小限に抑えることができます。
- 複数の保護されていないインスタンスが次の請求時間に最も近い場合、インスタンスをランダムに終了します。
カスタマイズされた終了ポリシー
- Auto Scaling は、最初に不均衡の AZ を評価します。AZ がグループで使用されている他の AZ よりも多くのインスタンスを持っている場合は、不均衡 AZ からインスタンスに対して指定された終了ポリシーを適用します。
- グループで使用されているアベイラビリティーゾーンが均衡している場合は、Auto Scaling よって、指定した終了ポリシーが適用されます。
- 次のカスタマイズされた終了ポリシーがサポートされます
- OldestInstance – グループ内で最も古いインスタンスを終了し、新しいインスタンスタイプにアップグレードする場合に役立ちます。
- NewestInstance – グループ内の最新のインスタンスを終了し、新しい起動構成をテストするときに役立ちます。
- OldestLaunchConfiguration – 最も古い起動構成を持つインスタンスを終了します。
- ClosestToNextInstanceHour – 次の請求時間に最も近いインスタンスを終了し、インスタンスの使用を最大化し、コストを管理するのに役立ちます。
- デフォルト – デフォルトの終了ポリシーに従って終了。
インスタンスの保護
- インスタンス保護では、Auto Scaling が特定のインスタンスを終了できるかどうかを制御します。
- インスタンス保護は、AUto Scaling グループまたは個々のインスタンスでも、いつでも有効にできます。
- インスタンス保護が有効になっている Auto Scaling グループ内で起動されたインスタンスは、そのプロパティを継承します。
- インスタンス保護は、インスタンスが InService であるとすぐに開始され、インスタンスが切り離されるとインスタンス保護が失われます。
- スケールインイベントが発生したときに、ASG 内のすべてのインスタンスが終了から保護されている場合、任意のインスタンスを終了できず、目的の容量がデクリメントされます。
- インスタンス保護は、以下のケースでは保護されません
- EC2 コンソール、terminate-instances コマンド、またはTerminateInstances APIによる手動終了。
- ヘルスチェックに失敗した場合には終了し、交換する必要があります。
- Auto Scaling グループ内のインスタンスを中断から検出。
スタンバイ状態
Auto Scaling を使用すると、InService インスタンスをスタンバイ状態にすることができます。その間、インスタンスは依然として ASG の一部ですが、要求は処理されません。 これは、インスタンスのトラブルシューティングやインスタンスの更新、インスタンスのサービスへの復帰に使用できます。
- インスタンスはスタンバイ状態にすることができ、終了しない限りスタンバイ状態のままになります。
- Auto Scaling は、既定では、グループの目的の容量をデクリメントし、新しいインスタンスを起動することを防ぎます。デクリメントが選択されていない場合は、新しいインスタンスを起動します。
- インスタンスがスタンバイ状態になると、インスタンスを更新したり、トラブルシューティングに使用したりできます。
- ロードバランサーが Auto Scaling に関連付けられている場合、インスタンスがスタンバイ状態になったときにインスタンスが自動的に登録され、インスタンスがスタンバイ状態を終了したときに再度登録が行われます。
サスペンション
- Auto Scaling プロセスは中断してから再開できます。これは、Auto Scaling プロセスをトリガーせずに、構成の問題を調査したり、アプリケーションの問題をデバッグしたりするのに非常に役立ちます。
- Auto Scaling では、24時間以上インスタンスを起動しようとしたが、インスタンスの起動に成功していない Auto Scaling グループの場合、ASG のプロセスを中断する管理サスペンションも実行されます。
- Auto Scaling には、
- Launch – グループに新しい EC2 インスタンスを追加し、その容量を増やします。
- Terminate – EC2 インスタンスをグループから削除し、その容量を減らします。
- HealthCheck -インスタンスの正常性をチェックします。
- ReplaceUnhealthy – 異常とマークされたインスタンスを終了し、それを置き換えるための新しいインスタンスを作成します。
- AlarmNotification –グループに関連付けられている Cloudwatch アラームからの通知を受け付けます。中断した場合、Auto Scaling ではアラームによって引き起こされるポリシーが自動的に実行されません。
- ScheduledActions – 作成するスケジュールされたアクションを実行します。
- AddToLoadBalancer – 起動時にインスタンスをロードバランサーに追加します。
- AZRebalance – グループ内の EC2 インスタンスの数を、リージョン内のアベイラビリティーゾーン間で分散します。
- AZ が ASG から削除されるか、または不健全または使用できなくなった場合、Auto Scaling は正常でない AZ で新しいインスタンスを起動してから、不健全または使用できないインスタンスを終了します。
- 正常でない AZ が健全な状態に戻ると、Auto Scaling は自動的にインスタンスをグループの可用性ゾーン全体に均等に再配布します。
- AZRebalance を一時停止し、スケールアウトまたはスケールアウトイベントが発生した場合でも、Auto Scaling によってアベイラビリティーゾーンのバランスが試行され、スケールアウト時にアベイラビリティーゾーンのインスタンスが最も少ないインスタンスで起動されることに注意してください。
- Launch を中断した場合、AZRebalance は新しいインスタンスを起動したり、既存のインスタンスを終了したりしません。これは、置換インスタンスを起動した後にのみ AZRebalance がインスタンスを終了するためです。
- Terminate をサスペンドすると、ASG は最大サイズよりも最大10%大きくなることがあります。これは、Auto Scaling がリバランス活動中にこれを一時的に許可するためです。 インスタンスを終了できない場合、ASG は Terminate プロセスが再開されるまでその最大サイズを超えたままになります。
Autoscaling & ELB
- AutoScaling & ELB についての記事を参照してください。
AWS認定試験の練習問題
- 質問はインターネットから収集され、答えは自分の知識と理解に基づいてマークされます(これはあなたと異なる場合があります)。
- AWSサービスは毎日更新され、回答と質問はすぐに時代遅れになる可能性がありますので、それに応じて調査してください。
- AWSのアップデートのペースを追うためにAWS試験の質問は更新されないため、基礎となる機能が変更されても質問が更新されないことがあります。
- さらなるフィードバック、ディスカッション、修正を可能にします。
- ユーザーは、Auto Scaling を使用して、スケジュールされたスケーリングアクティビティをセットアップしようとしています。ユーザーは、定期的なスケジュールを設定したいと考えています。この場合、以下で説明するパラメータのどれが必須ではありませんか?
- 最大サイズ
- Auto Scaling グループ名
- 終了時刻
- 繰り返し値
- ユーザーは、3つのインスタンスで Auto Scaling を構成しました。インスタンスのいずれかを更新した後、ユーザーが新しい AMI を作成しました。ユーザーが2つの特定のインスタンスを終了して、Auto
Scaling によって新しい起動構成でインスタンスが起動されるようにする場合は、どのコマンドを実行する必要がありますか。- as-delete-instance-in-auto-scaling-group –no-decrement-desired-capacity
- as-terminate-instance-in-auto-scaling-group –update-desired-capacity
- as-terminate-instance-in-auto-scaling-group –decrement-desired-capacity
- as-terminate-instance-in-auto-scaling-group –no-decrement-desired-capacity
- ユーザーは、8 A.M. によるアプリケーションのスケールアップと、Auto Scaling を使用した 7 P.M. による毎日のスケールダウンを計画しています。この場合、ユーザーは何を行う必要がありますか。
- Cloudwatch アラームに基づいてスケーリングポリシーを設定する。
- ユーザーは 8 A.M. で所望の容量を増加し、手動で 7 P.M. によってそれを減少させる必要があります。
- ユーザーは、特定の時刻に EC2 インスタンスを起動するバッチ処理をセットアップする必要があります。
- 特定の時間にスケールアップまたはダウンするようにスケジュールされたアクションをセットアップする。
- 組織は、ELB を使用して Auto Scaling を設定しています。いくつかの手動エラーが原因で、インスタンスの1つが再起動されました。したがって、Auto Scaling のヘルスチェックに失敗しました。Auto Scaling では、置き換えのマークが付けられています。どのようにシステム管理者は、インスタンスが終了しないことを確認できますか?
- Auto Scaling グループを更新してインスタンスの再起動イベントを無視する。
- それは交換のためにマークされた後、ステータスを変更することはできません。
- 再起動後にそのインスタンスを自動スケーリンググループに手動で追加する。
- Auto Scaling コマンドを使用して、インスタンスの正常性を [正常] に変更する。
- ユーザーは、最小容量を 2 とし、希望する容量を 2 として Auto Scaling を構成しています。ユーザーは、次のコマンドを使用して、既存のインスタンスのいずれかを終了しようとしています: as-terminate-instance-in-auto-scaling-group –decrement-desired-capacity. このシナリオでは、Auto Scaling は何を行いますか?
- インスタンスを終了し、新しいインスタンスを起動しません。
- インスタンスを終了し、必要な容量を1に更新します。
- インスタンスを終了し、必要な容量と最小サイズを1に更新します。
- エラーを投げます
- 組織は、アプリケーションをホストするための Auto Scaling を構成しています。システム管理者は、Auto Scaling のヘルスチェックプロセスを理解したいと考えています。インスタンスが異常である場合、Auto Scaling はインスタンスを起動し、異常なインスタンスを終了します。注文の実行とは何ですか?
- Auto Scaling は新しいインスタンスを最初に起動し、次に異常なインスタンスを終了します。
- Auto Scaling は、ランダムな順序で起動および終了プロセスを実行します。
- Auto Scaling によるインスタンスの同時起動と終了。
- Auto Scaling はインスタンスを最初に終了し、次に新しいインスタンスを起動します。
- ユーザーが Auto Scaling を使用して ELB を構成しました。ユーザーは、Auto Scaling の終了処理をしばらく中断しました。この期間中、アベイラビリティーゾーンのリバランスプロセス (AZRebalance) はどうなるのでしょうか?
- Auto Scaling は、インスタンスを起動または終了しません。
- Auto Scaling により、インスタンスが最大サイズよりも大きくなるようになります。
- Auto Scaling によってインスタンスの最大サイズまでの起動が維持される。
- 起動をアクティブな状態に保ちながら、終了プロセスを中断することはできません。
- 組織は、ELB を使用して Auto Scaling を構成しました。CPU 使用率が 90% を超える原因となっているアプリケーションには、メモリの問題があります。CPU 使用率が高いほど、スケーリングポリシーに従って自動スケーリングのイベントがトリガされます。ユーザーがスケーリングアクティビティをトリガーせずにアプリケーション内の根本原因を見つけたい場合は、どのようにしてこれを実現できますか?
- リサーチが完了するまでスケーリングプロセスを停止する。
- スケーリングをトリガすることなく、そのインスタンスから根本原因を見つけることはできません。
- リサーチが完了するまで Auto Scaling スケーリングを削除する。
- リサーチが完了するまでスケーリングプロセスを中断する。
- ユーザーが Auto Scaling を使用して ELB を構成しました。ユーザーは、Auto Scaling アラーム通知 (cloudwatch アラームの Auto Scaling を通知する) プロセスを一時停止しました。この期間中に Auto Scaling は何を行いますか?
- AWS は Cloudwatch からアラームを受信しません。
- AWS はアラームを受け取りますが、Auto Scaling ポリシーは実行されません。
- Auto Scaling はポリシーを実行しますが、プロセスが再開されるまでインスタンスを起動しません。
- AlarmNotification プロセスを中断することはできません。
- 組織は、2つの単一アベイラビリティーゾーンを構成しました。Auto Scaling グループは、別のゾーンで構成されます。ユーザーは、1つのグループが複数のゾーンにまたがるようにグループを結合する必要があります。どのようにユーザーがこれを構成できますか?
- as-join-auto-scaling-group コマンドを実行して2つのグループを結合します。
- as-update-auto-scaling-group コマンドを実行して、あるグループを複数のゾーンにまたがるように設定し、他のグループを削除します。
- as-copy-auto-scaling-group コマンドを実行して、2つのグループに参加します。
- as-merge-auto-scaling-group コマンドを実行して、グループをマージする。
- 組織はELBで Auto Scaling を設定しました。インスタンスヘルスチェックの1つでは、障害が発生したことを Auto Scaling に戻します。このシナリオで Auto Scaling は何をしますか?
- インスタンスが失敗したことを宣言する前に、クールダウンするまでヘルスチェックを実行する
- インスタンスを終了し、新しいインスタンスを起動します
- 障害状態の SNS を使用してユーザーに通知する
- 障害のあるインスタンスへのトラフィックの送信を停止するように ELB に通知する
- ユーザーは Auto Scaling グループを設定しています。グループは24時間以上単一のインスタンスを起動できませんでした。この状態で Atuo Scaling はどうなりますか?
- Auto Scaling は72時間のためのインスタンスを起動しようとし続ける
- Auto Scaling によりスケーリング処理が中断される
- Auto Scaling により、別のリージョンでインスタンスが開始されます
- Auto Scaling グループは自動的に終了されます
- ユーザーはクリスマスセールスのために AWS にインフラストラクチャをセットアップする予定です。 ユーザーは、プロアクティブスケーリングのスケジュールに基づいて Auto Scaling を使用する予定です。ユーザーに何をアドバイスしますか?
- ユーザーが後でそれを忘れた場合、スケールアップしないので、今はスケジュールするのが良いです。
- スケジューリングは、クリスマスの前に1週間だけ設定する必要があります。
- アクティビティをスケジュールする前に11月末まで待ってください。
- スケジュールベースのスケーリングを使用することはお勧めしません。
- ユーザーが繰り返し Auto Scaling 処理を設定しようとしています。 ユーザーは毎日午前8時にスケールアップし、午後7時にスケールダウンする1つのプロセスをセットアップしています。 ユーザーは毎月1日に午前8時にスケールアップし、午後7時に同じ日にスケールアップする別の定期的なプロセスをセットアップしようとしています。 このシナリオで Auto Scaling は何を行いますか?
- Auto Scaling は両方のプロセスを実行しますが、1つのインスタンスだけを追加します。
- Auto Scaling は、月の1日に2つのインスタンスを追加します
- Auto Scaling はプロセスの両方をスケジュールしますが、1つのプロセスだけをランダムに実行します。
- AUto Scaling は、2つの個別の Auto Scaling プロセスのスケジュールに矛盾があるため、エラーを投げます。
- システム管理者は、Auto Scaling アクティビティを理解しようとしています。Auto Scaling では以下のどのプロセスが実行されませんか?
- インスタンスの再起動
- スケジュールアクション
- 不健康な置換
- アベイラビリティーゾーンの再バランシング
- 新しいジョブを開始し、AWS の会社のインフラストラクチャを確認しています。1つの Web アプリケーションが、Auto Scaling グループの Web インスタンスの前に ELB を持っていることに気付きました。Cloudwatch の ELB
のメトリックを確認すると、可用性ゾーン(AZ)Aでは4つの正常なインスタンスが表示され、AZ Bではゼロが表示されます。不健全なインスタンスはゼロです。 AZ 間のインスタンスのバランスをとるために修正する必要があるのは何ですか?- ELB を別の AZ にのみアタッチするように設定する
- Auto Scaling が両方の AZ で起動するように構成されていることを確認します
- AMI が両方の AZ で使用可能であることを確認します。
- Auto Scaling グループの最大サイズが4より大きいことを確認します
- Amazon VPC EC2 と SQS を活用して、毎秒何百万ものメッセージをメッセージキューに送信して受信するアプリケーションを実装するよう求められました。 アプリケーションで EC2 インスタンスと SQS の間に十分な帯域幅が確保されていることを確認する必要があります。 アプリケーションと SQS 間の通信に最も拡張性の高いソリューションを提供するオプションはどれですか?
- アプリケーションインスタンスが ELB で正しく構成されていることを確認する
- アプリケーションインスタンスが、EBS 最適化オプションが有効になっているプライベートサブネットで起動されていることを確認する
- アプリケーションインスタンスがパブリックサブネットで起動されていることを、パブリック IP アドレス = trueoption が有効になっていることを確認します。
- Auto Scaling グループと SQS キューサイズを監視するように構成された Auto Scaling トリガーを使用して、プライベートサブネット内でアプリケーションインスタンスを起動する。
- Auto Scaling を使用しているアプリケーション層で実行されているインスタンスのインスタンスのタイプを変更することに決めました。 下のどの領域でインスタンスのタイプ定義を変更しますか?
- Auto Scaling 起動設定
- Auto Scaling グループ
- Auto Scaling ポリシー
- Auto Scaling タグ
- ユーザーが CLI から Auto Scaling グループを削除しようとしています。 次のステップのどれがユーザーによって実行されるのですか?
- ec2-terminate-instance コマンドでインスタンスを終了する
- as-terminate-instanceコマンドを使用して Auto Scaling インスタンスを終了する
- 最小サイズと希望する容量を 0 に設定する
- 容量を変更する必要はありません。 as-delete-groupコマンドを実行すると、すべての値が0にリセットされます
- ユーザーが Auto Scaling を使用して Web アプリケーションを作成しました。 ユーザーはアプリケーションを定期的に監視しており、木曜日と金曜日の午前8時から午後6時の間にトラフィックが最も高いことを確認しました。 この場合スケーリングを処理する最適なソリューションは何ですか?
- 月曜日午前8時までに新しいインスタンスを手動で追加し、金曜日の午後6時までにインスタンスを終了する
- 月曜日午前8時にスケールアップし、金曜日の午後6時以降にスケールを縮小するようスケジューリングする
- 毎日午前8時にスケールアップされ、午後6時にスケールアップされるポリシーをスケジュールします。
- バッチ処理を設定してインスタンスを午前8時に追加し、金曜日午後6時までに削除する
- ユーザは、最小容量を3、最大容量を5として Auto Scaling グループを設定しました。ユーザが AS グループを設定すると、Auto Scaling が起動するインスタンスの数はいくつですか?
- 3
- 0
- 5
- 2
- システム管理者は AWS 上でアプリケーションを管理しています。 アプリケーションは EC2 にインストールされ、ユーザーは ELB と Auto Scaling を設定しています。 今後の負荷の増加を考慮して、ユーザーは ELB に登録されるように積極的に新しいサーバーを立ち上げる予定です。 ユーザーはこれらのインスタンスを Auto Scaling でどのように追加できますか?
- Auto Scaling グループの望ましい容量を増やす
- Auto Scaling グループの上限を増やす
- 手作業でインスタンスを起動し、その場で ELB に登録する
- Auto Scaling グループの最小制限を減らす
- アプリケーションの Auto Scaling イベントを見直すと、アプリケーションは同じ時間内に複数回スケールアップされます。 弾力性を維持しながらコストを最適化するためには、どのような設計選択肢がありますか? 2つの答えを選択してください。
- Auto Scaling スケールダウンポリシーをトリガーする Amazon CloudWatch アラーム期間を変更します。
- Auto Scaling グループ終了ポリシーを変更して、最も古いインスタンスを最初に終了します。
- スケジュールされたスケーリングアクションを使用するように Auto Scaling ポリシーを変更します。
- Auto Scaling グループクールダウンタイマーを変更します。
- 最新のインスタンスを最初に終了するように Auto Scaling グループ終了ポリシーを変更します。
- Elastic Load Balancing と Auto Scaling を使用して、1つのリージョンの2つの AZ に現在デプロイされているビジネス上重要な2層 Web アプリケーションがあります。 このアプリケーションは、データベースレイヤでの同期レプリケーション(非常に短い遅延接続)に依存します。 1つのアプリケーション AZ がオフラインになり、残りの AZ に Auto Scaling が新しいインスタンスを起動できない場合でも、アプリケーションは完全に利用可能でなければなりません。 これを確実にするために現在のアーキテクチャをどのように強化できますか? [プロフェッショナル]
- Weighted Round Robin(WRR)を使用して2つのリージョンに配置し、Auto Scaling の最小値をリージョンあたり100%ピーク負荷に設定します
- 3つの AZ に展開し、Auto Scaling の最小設定はゾーンごとのピーク負荷の 50% を処理します。
- 3つの AZ に展開し、Auto Scaling スケーリングを最小限に設定してゾーンあたりのピーク負荷を 33% 処理します。(オートスケーリングも失敗した場合は、1つの AZ の損失は66%しか処理されません)
- Weighted Round Robin(WRR)を使用して2つの領域に展開し、Auto Scaling の最小値をリージョンあたり50%のピーク負荷に設定します。
- CloudWatch の詳細な監視が無効になっている Auto Scaling の起動構成が作成されました。 ユーザーは詳細な監視を有効にしたいと考えています。 ユーザーはどのようにこれを達成できますか?
- CLI を使用して起動設定を更新して、InstanceMonitoringDisabled = falseを設定します。
- 詳細な監視を有効にするには、AWS コンソールから Auto Scaling グループを変更する必要があります。
- CLI を使用して起動設定を更新して、InstanceMonitoring.Enabled = trueを設定します。
- 詳細監視を有効にして新しい起動設定を作成し、自動スケーリンググループを更新します
- ユーザは、CLI からデフォルト設定の Auto Scaling グループを作成しました。 ユーザーは、Auto Scaling グループによって起動された EC2 インスタンスで CloudWatch アラームをセットアップする必要があります。ユーザーは毎分 CPU 使用率を監視するアラームを設定しています。 次のうちどれに該当するのか?
- EC2 基本監視メトリックは5分ごとに収集されるため、1分ごとにデータをフェッチしますが、4つのデータポイント[4分に対応]は値を持たない
- Auto Scaling のデフォルトの起動設定によって、EC2の詳細な監視が有効になるため、毎分のデータを取得します
- ユーザが EC2 インスタンスの詳細な監視を有効にしていないため、アラームの作成は失敗します
- ユーザは、EC2 インスタンスの詳細な監視を有効にして、毎分アラーム監視をサポートする必要があります
- 顧客は、市場全体で利用可能なすべての取引を表示するウェブサイトを持っています。 このサイトでは一般に5つの大きな EC2 インスタンスの負荷が発生します。 しかし、感謝祭の休暇の1週間前に、彼らはほぼ 20 の大きなインスタンスの負荷に遭遇します。 その期間中の負荷は、オフィスのタイミングに基づいて日によって異なります。 以下のうちどれが費用効果が高く、ウェブサイトのパフォーマンス向上に役立つのでしょうか?
- 営業時間内には 10 インスタンスのみを実行し、毎日 10 インスタンスを手動で起動します。
- プレ・バケーション期間中に 10 インスタンスを実行するように設定し、Auto Scaling スケジュールを使用してさらに 10 インスタンスを起動して、オフィス時間中にスケールアップするだけです。
- 休暇前の期間に、ネットワーク I/O ポリシーに基づいて Auto Scaling を使用して、組織に15のインスタンスが実行され、5つのインスタンスが拡大縮小するシナリオを設定します。
- 休暇期間中に、20 のインスタンスを連続して実行するように設定します。
- Auto Scaling が条件に基づいて新しいインスタンスを起動しているとき、以下に述べるポリシーのどれがそれに従うのですか?
- クロスゾーンロードバランシングで定義された基準に基づいて
- 最高の負荷分散を持つインスタンスを起動する
- 少数のインスタンスで AZ のインスタンスを起動する
- 最高のインスタンスを持つAZのインスタンスを起動する
- ユーザーが複数の Auto Scaling グループを作成しました。 ユーザーは新しい AS グループを作成しようとしていますが、失敗します。 そのリージョンの Auto Scaling で指定されたASグループの上限に達したことをユーザーはどのように知ることができますか?
- 次のコマンドを実行します。as-describe-account-limits
- 次のコマンドを実行します。as-describe-group-limits
- 次のコマンドを実行します。as-max-account-limits
- 次のコマンドを実行します。as-list-account-limits
- ユーザーが AWS サービスの費用を節約しようとしています。 次のうちどれが費用を節約するのに役立たないでしょうか?
- インスタンスが終了したら未使用の EBS ボリュームを削除する
- インスタンスが終了した後で Auto Scaling の起動設定を削除する(Auto Scaling起動設定には何もかかりません)
- インスタンスが終了した後、必須でない場合はエラスティックIPを解放する
- インスタンスが終了した後の AWS ELB の削除
- 手動 Auto Scaling を使用して AWS リソースをスケールアップするには、以下のパラメータのうちどれを変更する必要がありますか?
- 最大容量
- 望ましい容量
- 好ましい容量
- 現在の容量
- AWS Auto Scaling では、スタンバイモードで定常状態から離れると、既存インスタンスが最初に入力する遷移状態は何ですか?
- 切り離す
- 終了中:待機
- 保留中(InService 状態のインスタンスをスタンバイ状態にすることができます。これにより、インスタンスをサービスから削除したり、トラブルシューティングしたり、変更したり、サービスに戻したりすることができます。 Auto Scaling グループによって管理されますが、サービスに戻すまではアプリケーションのアクティブな部分ではありません。)
- EnterStandby
- AWS Auto Scaling では、ヘルスチェックの失敗または負荷の低下によるスケーリングイン時に、定常状態から退出した後にインスタンスが最初に入力する遷移状態は何ですか?
- 終了(Auto Scaling がイベントのスケールに応答すると、1つまたは複数のインスタンスを終了します)これらのインスタンスは Auto Scaling グループから切り離され、Terminating ステートになります。
- 切り離す
- 終了中:待機
- EnterStandby
- ユーザーは、EC2 インスタンスで ELB を使用して Auto Scaling を設定しています。 ユーザーは、CPU 使用率が 10% を下回るたびに Auto Scaling が1つのインスタンスを削除するように設定する必要があります。 ユーザーはどのようにこれを設定できますか?
- CPU 使用率が 10% 未満の場合、SNS を使用して電子メールを取得できます。 ユーザーは、Auto Scaling の望ましい容量を使用してインスタンスを削除できます
- CloudWatch を使用してデータを監視し、自動スケーリングを使用してスケジュールされたアクションを使用してインスタンスを削除する
- Auto Scaling に通知を送信するように CloudWatch を設定する CPU 使用率が 10% 未満のときに構成を起動し、自動スケーリングポリシーを設定してインスタンスを削除する
- CPU 使用率が 10% 未満の場合に Auto Scaling グループに通知を送信し、Auto Scaling ポリシーを設定してインスタンスを削除するように CloudWatch を設定します
- ユーザーは、Auto Scaling グループ で詳細な CloudWatch メトリック監視を有効にしました。 以下のメトリックのどれが、保留中、終了中、実行中のインスタンスを含む Auto Scaling グループ内のインスタンスの総数を特定するのに役立ちますか?
- GroupTotalInstances(リンクを参照)
- GroupSumInstances
- 3つのメトリックをすべて集計することはできません。 ユーザは、実行中のインスタンス、終了中のインスタンス、および保留中のインスタンスの個数を見つけて合計しなければなりません
- GroupInstancesCount
- あなたのスタートアップは、あなたの最初の日に10オーダーを期待する6ヶ月以上かかるオーダーで、生産するのに平均3〜4日必要なパーソナライズされたガジェットを販売するためのオーダーフルフィルメントプロセスを実装したいと考えています。 6ヵ月後に1日当たり1000件、12ヵ月後に1万件注文します。入ってくる注文は、一貫性があるかどうかチェックされ、生産品質管理パッケージ出荷と支払い処理のために製造工場に発送されます。製品がプロセスのどの段階でも品質基準を満たしていない場合、従業員はプロセスにステップを繰り返すことがあります。顧客は、注文状況や支払いの失敗などの注文に関する重大な問題について電子メールで通知されます。お客様のケースアーキテクチャーには、お客様のデータおよびオーダー用の RDS MySQL インスタンスを使用して、お客様の Web サイト用の AWS Elastic Beanstalk が含まれています。電子メールが確実に配信されていることを確認しながら、注文の履行プロセスをどのように実装できますか? [プロフェッショナル]
- Elastic Beanstalk アプリケーションサーバーにビジネスプロセス管理アプリケーションを追加し、注文状態を追跡するために ROS データベースを再利用する Elastic Beanstalk インスタンスの1つを使用して顧客に電子メールを送信します。
- アクティビティワーカーの Auto Scaling グループを持つ SWF と、min / max = 1の別の Auto Scaling グループの decider インスタンスを使用します。decider インスタンスを使用して、顧客に電子メールを送信します。
- アクティビティワーカーの Auto Scaling グループを持つ SWF とmin / max = 1の別の Auto Scaling グループの decider インスタンスを使用して、SES を使用して顧客に電子メールを送信します。
- SQS キューを使用してすべてのプロセスタスクを管理する EC2 インスタンスの自動スケーリンググループを使用して、タスクをポーリングして実行します。顧客に電子メールを送信するには、SES を使用します。