
Jayendra’s Blog
この記事は自己学習用に「AWS Auto Scaling & ELB(Jayendra’s Blogより)」を日本語に訳した記事です。
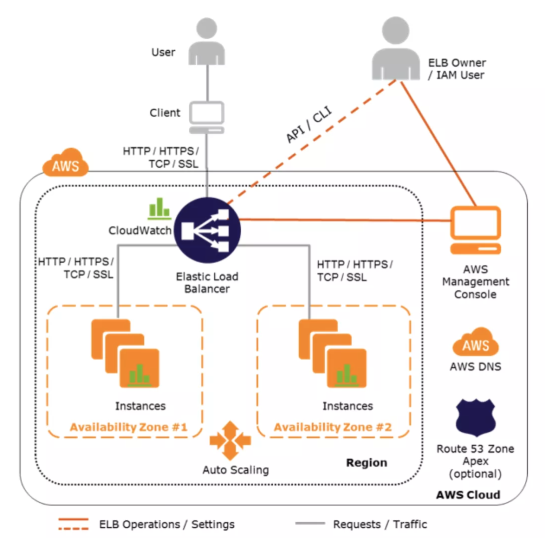
Auto Scaling & ELB
- Auto Scaling によって EC2 インスタンスが動的に追加および削除されますが、ELB では、1つのインスタンスが圧倒されないようにトラフィックを最適にルーティングすることで、着信要求を管理。
- Auto Scaling により、ユーザーの要求が上がると EC2 インスタンスの数が自動的に増加し、要求がダウンしたときに EC2 インスタンスの数を減らすことができます。
- ELB サービスは、実行中のすべての EC2 インスタンス間で、着信 Web トラフィック (ロードと呼ばれる) を自動的に配布するのに役立ちます。
- ELB は、ロードバランサーを使用してトラフィックを監視し、インターネットを介して要求を処理します。
- ELB & Auto Scaling の使用
- 動的に変化する EC2 インスタンス群にトラフィックをルーティングすることが容易になります。
- ロードバランサは、Auto Scaling グループ内のインスタンスへのすべての着信トラフィックに対して単一のコンタクトポイントとして機能します。
Auto Scaling グループを使用した ELB のアタッチ/デタッチ
- Auto Scaling は、ELB と統合され、既存の Auto Scaling グループに1つ以上のロードバランサーをアタッチできます。
- ELB は、その IP アドレスを使用して EC2 インスタンスを登録し、リクエストをインスタンスのプライマリインタフェース (eth0) のプライマリ ip アドレスにルーティングします。
- ELB がアタッチされた後、グループ内のインスタンスを自動的に登録し、インスタンス間で受信トラフィックを分散します。
- ELB がデタッチされると、グループ内のインスタンスを登録しながら、削除状態に入ります。
- 接続のドレインが有効になっている場合、ELB は実行中のリクエストが完了するのを待ってから、インスタンスの登録を解除します。
- インスタンスは、ELB から登録された後も実行されたままです。
- Auto Scaling では、起動中にインスタンスが ELB に追加されますが、中断することができます。停止期間中に起動されたインスタンスは、ロードバランサーに追加されず、再開後に手動で登録する必要があります。
高可用性と冗長性
- Auto Scaling は、同じリージョン内で複数の AZ にまたがることができます。
- 1つの AZ が異常または使用できなくなった場合、Auto Scaling は影響を受けない AZ で新しいインスタンスを起動します。
- 不健全な AZ が復旧すると、Auto Scaling はすべての正常な AZ にトラフィックを再配布します。
- ELB は、単一の AZ またはリージョン内の複数の AZ で、EC2 インスタンス間で受信要求を分散するように設定できます。
- Auto Scaling & ELB を使用して、リージョン内の複数の AZ にまたがる Auto Scaling グループをスパンし、ELB を設定してそれらの AZ 間で受信トラフィックを分散することにより、地理的冗長性の安全性と信頼性を活用することをお勧めします。
- 受信トラフィックは、ELB で有効になっているすべての AZ に均等に負荷分散されます。
ヘルスチェック
- Auto Scaling グループは、EC2 インスタンスステータスチェックの結果を定期的にチェックすることにより、各インスタンスのヘルス状態を決定します。
- インスタンスが EC2 インスタンスのステータスチェックに失敗した場合、Auto Scaling はインスタンスを異常としてマークし、インスタンスを置き換えます。
- また、ELB は、それに登録されている EC2 インスタンスのヘルスチェックを実行します。アプリケーションは、ping とヘルスチェックページで利用可能です。
- Auto Scaling は、既定では、ELB の正常性チェックが失敗した場合、インスタンスを置き換えません。
- インスタンスに ELB ヘルスチェックを使用して、トラフィックが正常なインスタンスにのみルーティングされるようにする必要があります。
- Auto Scaling グループにロードバランサーを登録した後は、EC2 インスタンスのステータスチェックに加えて、ELB ヘルスチェックの結果を使用して、Auto Scaling グループ内の EC2 インスタンスの状態を判断するように構成できます。
監視
- ELBは、ロードバランサーと EC2 インスタンスに関するデータを Amazon Cloudwatch に送信します。Cloudwatch は、リソースのパフォーマンスに関するデータを収集し、メトリックスとして提示します。
- Auto Scaling グループを使用して1つ以上のロードバランサーを登録した後、Auto Scaling グループは、アプリケーションを自動的にスケーリングするために、ELB メトリック (要求の待ち時間や要求数など) を使うように構成できます。
AWS認定試験の練習問題
- 質問はインターネットから収集され、答えは自分の知識と理解に基づいてマークされます(これはあなたと異なる場合があります)。
- AWSサービスは毎日更新され、回答と質問はすぐに時代遅れになる可能性がありますので、それに応じて調査してください。
- AWSのアップデートのペースを追うためにAWS試験の質問は更新されないため、基礎となる機能が変更されても質問が更新されないことがあります。
- さらなるフィードバック、ディスカッション、修正を可能にします。
- 企業は、動的なトランザクションベースのコンテンツを提供するために、2層の web アプリケーションを構築しています。データ層は、オンライントランザクション処理 (OLTP) データベースを活用しています。エラスティックおよびスケーラブルな web 層を有効にするには、どのようなサービスを活用する必要がありますか。
- ELB、amazon EC2、および Auto Scaling
- ELB、マルチ AZ による Amazon RDS、および Amazon S3
- マルチ AZ と Auto Scaling を備えた Amazon RDS
- Amazon EC2、Amazon DynamoDB、および Amazon S3
- 大規模な組織の AWS インフラストラクチャを展開するためのスコープが与えられています。要件は、多くの EC2 インスタンスを持っていますが、Amazon EC2 フリートの平均使用率が高く、CPU 使用率が低いときに逆にそれらを削除する場合に追加する必要がある場合があります。これを実現するには、どの AWS サービスを使用するのが最適でしょうか。
- Amazon CloudFront、Amazon Cloudwatch、およびELB
- Auto Scaling 、Amazon Cloudwatch と AWS Cloudtrail
- Auto Scaling 、Amazon Cloudwatch、および ELB
- Auto Scaling 、Amazon Cloudwatch および AWS Elasticbean
- ユーザーが Auto Scaling を使用して ELB を構成しました。ユーザーは Auto Scaling AddToLoadBalancer を中断し、インスタンスをロードバランサーに追加します。しばらくの間、処理します。停止期間中に起動されたインスタンスはどうなるのでしょうか。
- インスタンスは ELB に登録されず、ユーザーはプロセスの再開時に手動で登録することができます。
- インスタンスは、プロセスが再開された後にのみ ELB に登録します。
- Auto Scaling では、プロセス停止のためにこの期間中にインスタンスを起動しません。
- AddToLoadBalancer プロセスのみを中断することはできません。
- Auto Scaling グループは、ELB に関連付けられています。Auto Scaling グループを介して起動されたインスタンスが、ELB ヘルスチェックのために異常とマークされていることに気付きましたが、これらの異常なインスタンスは終了されていません。ELB によって異常をマークされたトライアルインスタンスが終了して置き換えられるようにするには、何をする必要がありますか。
- AUto Scaling グループのヘルスチェックに設定されているしきい値を変更する。
- Auto Scaling グループに ELB のヘルスチェックを追加する。
- ELB で設定されているヘルスチェック間隔の値を大きくする。
- ELB のヘルスチェックセットを変更して、http チェックではなく TCP を使用する
- Amazon EC2 インスタンスの Auto Scaling グループの前で、ELB で構成される web アプリケーションを担当します。新しいバージョンのアプリケーションの最近の展開では、新しい AMI が作成され、Auto Scaling グループがこの新しい AMI を参照する新しい起動構成で更新されました。展開中に、web サイトがエラーで応答していることをユーザーから苦情が届きました。すべてのインスタンスは、ELB ヘルスチェックに合格しました。今後の展開でエラーが発生しないようにするにはどうすればよいですか。(2 回答を選択)[PROFESSIONAL]
- Auto Scaling 自動スケーリンググループにエラスティック負荷分散ヘルスチェックを追加します。ロードバランサーへのインスタンスの早期登録を防ぐために、できるだけ早く稼働するようにヘルスチェックの短い期間を設定します。
- EC2 インスタンス Cloudwatch アラートを有効にして、起動設定の AMI を前のものに変更します。新しい AMI を使用しているインスタンスを徐々に終了します。
- アプリケーションの正常性を完全にテストし、テストが失敗した場合にエラーが返されるようにするために、ELB のヘルスチェック構成を設定します。
- 新しい AMI を参照する新しい起動構成を作成し、グループに関連付けます。グループのサイズを2倍にして、新しいインスタンスが正常になるまで待ち、元のサイズに戻します。新しいインスタンスが正常にならない場合は、以前の起動構成を関連付けます。
- ELB 不健全しきい値を高くして、不健全なインスタンスがロードバランサの背後で動作しないようにします。
- 最も高速なスケーリングの順序 (最初にスケールするのが最速) とは何ですか。a) EC2 + ELB + Auto Scaling b) Lambda c) RDS
- b, a, c (lambda は即座にスケーリングするように設計されています。EC2 + ELB + Auto Scaling では、スケールアウトするには1桁分が必要です。RDS では、少なくとも15分かかりますが、OS パッチやその他の更新プログラムが適用された場合、その他のアップデートを行います)。
- c, b, a
- c、a、b
- a、c、b
- ユーザーが EC2 インスタンスでアプリケーションをホストしました。EC2 インスタンスは、ELB と AutoScaling を使用して構成されます。アプリケーションサーバーセッションのタイムアウトは2時間です。ユーザーは、インスタンスが登録されているにもかかわらず、すべての機内要求が ELB によってサポートされていることを確認するために、接続のドレインを構成したいと考えています。ユーザーが接続のドレインを指定するには、どのようなタイムアウト期間が必要ですか?
- 5分
- 1時間 (最大許容は、実行中の要求が生きているのを保つために2時間に近い3600秒です)
- 30分
- 2時間
コメントを残す