AWS S3 ストレージクラスの概要
- Amazon S3 ストレージクラスは、1つまたは2つの施設のデータの同時損失を維持するように設計されています。
- S3 ストレージクラスは、コスト削減のためのオブジェクトの自動移行のためのライフサイクル管理を可能にする。
- S3 ストレージクラスは、転送中のデータの SSL 暗号化をサポートし、残りのデータ暗号化。
- また、S3 はチェックサムを使用してデータの完全性を定期的に検証し、自動修復機能を提供します。
標準
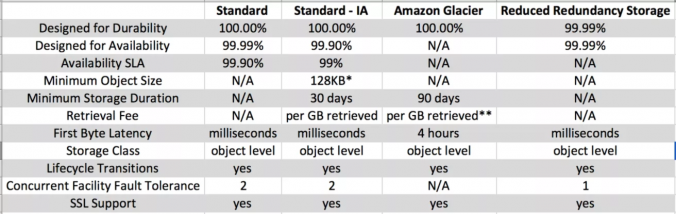
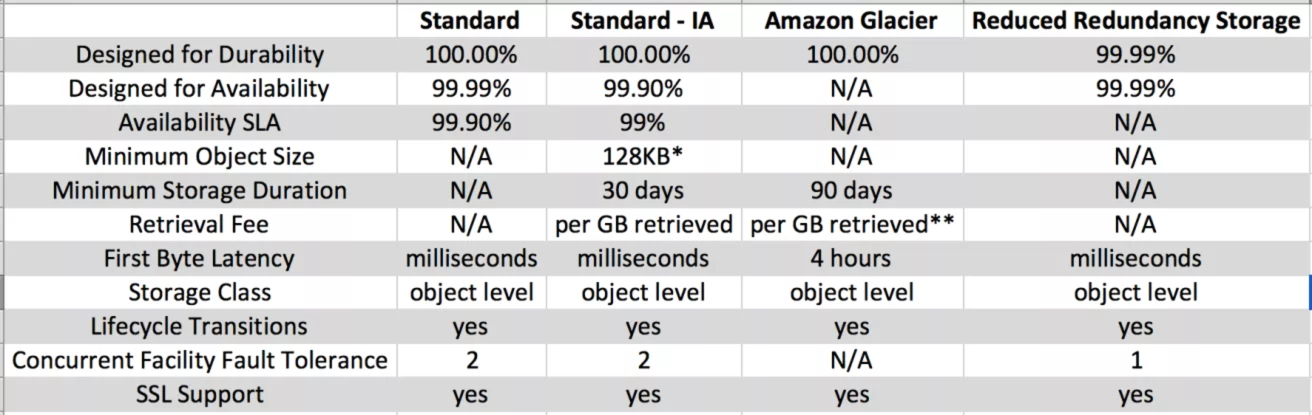
- ストレージクラスは、パフォーマンスに敏感なユースケースと頻繁にアクセスされるデータに最適であり、2つの施設でデータの損失を維持するように設計されています。
- 標準は、アップロード中に指定されていない場合、デフォルトのストレージクラスです。
- 低レイテンシと高スループット性能。
- オブジェクトの 99.999999999% の耐久性のために設計されています。
- 特定の年の 99.99% の可用性のために設計されています。
- 可用性のための Amazon S3 サービスレベル契約 に裏づけされています。
標準IA
- S3 標準IA (アクセス頻度の低い) ストレージクラスは、アクセスが制限されているバックアップや古いデータなどの、長寿命でアクセス頻度の低いデータに最適化されていますが、ユースケースは依然として高いパフォーマンスを要求します。
- 標準IA は、2つの施設でデータの損失を維持するために設計されています。
- 標準IA オブジェクトは、リアルタイムアクセスに使用できます。
- 標準IA ストレージクラスは、128 KB を超える大規模なオブジェクトに適しています (小さいオブジェクトは128KB に対してのみ課金されます)、少なくとも30日間保管します。
- 同一の低レイテンシと高スループット性能の標準装備。
- オブジェクトの 99.999999999% の耐久性のために設計されています。
- 年にわたって 99.9% の可用性のために設計に設計されています。
- 可用性のための Amazon S3 サービスレベル契約に裏づけされています。
低冗長化ストレージ(RRS)
- 低冗長性ストレージ (RRS) ストレージクラスは、標準ストレージクラスよりも低いレベルの冗長性で保存された、重要で再現できないデータ用に設計されているため、ストレージコストが削減されます。
- オブジェクトの 99.99% の耐久性のために設計されています。
- 年にわたって 99.99% の可用性のために設計されています。
- 低レベルの冗長性により、耐久性と可用性が低下します。
- RRS は複数の施設にまたがって複数のデバイスにオブジェクトを格納し、一般的なディスクドライブの400倍の耐久性を提供します。
- RRS は、S3 標準ストレージとして何度もオブジェクトをレプリケートせず、単一の施設でのデータ消失を維持するように設計されています。
- RRS オブジェクトが失われた場合、S3 はそのオブジェクトに対して行われた要求に対して405エラーを返します。
- S3 は、バケット上で構成されたイベント通知を送信したり、ユーザに警告したり、失われたオブジェクトを置き換えるために使用できる RRS オブジェクトが失われたことを検出したときにワークフローを開始したりできます。
Glacier
- Glacier のストレージクラスは、データのアクセスがまれであり、いくつかの (3-5) 時間の取得時間が許容されるデータをアーカイブするために適しています。
- Glacier のストレージクラスは、非常に低コストの Amazon Glacier ストレージサービスを使用しますが、このストレージクラス内のオブジェクトはまだ S3 を介して管理されます。
- オブジェクトの 99.999999999% の耐久性のために設計されています。
- Glacier は、オブジェクト作成時にストレージクラスとして指定することはできませんが、ライフサイクル管理を使用して標準、RRS、または標準IAから Glacier ストレージクラスに移行する必要があります。
- Glacier オブジェクトにアクセスするには、
- オブジェクトを復元する必要があります。これは3〜5時間の間に行われます。
- オブジェクトは、復元要求時に指定された期間 (日数) に対してのみ使用できます。
- オブジェクトのストレージクラスは Glacier のまま。
- 料金は、アーカイブ (Glacier 率) とコピーが一時的に復元 (RRSレート) の両方に課税されます。
- ボルトロック機能は、ロック可能なポリシーによるコンプライアンスを強制します。
AWS認定試験の練習問題
- 質問はインターネットから収集され、答えは自分の知識と理解に基づいてマークされます(これはあなたと異なる場合があります)。
- AWSサービスは毎日更新され、回答と質問はすぐに時代遅れになる可能性がありますので、それに応じて調査してください。
- AWSのアップデートのペースを追うためにAWS試験の質問は更新されないため、基礎となる機能が変更されても質問が更新されないことがあります。
- さらなるフィードバック、ディスカッション、修正を可能にします。
- S3について語るとき、RRSは何を表しますか?
- Redundancy Removal System
- Relational Rights Storage
- Regional Rights Standard
- Reduced Redundancy Storage
- S3 RRS の耐久性は?
- 99.99%
- 99.95%
- 99.995%
- 99.999999999%
- Amazon S3 の低冗長性オプションについて教えてください。
- 低コストでの冗長性の低減
- amazon S3 には存在しませんが、amazon EBS ではありません。
- それはあなたが特定の管轄外のファイルの任意のコピーを破棄することができます。
- まったく存在しません
- アプリケーションが5分ごとにログファイルを生成しています。ログファイルは重要ではありませんが、いくつかの重大な問題の場合にのみ検証に必要な場合があります。ファイルは、必要に応じてインターネット経由でアクセスできる必要があります。以下のオプションのうちどれがそれのための最良のストレージソリューションですか?
- AWS S3
- AWS Glacier
- AWS RDS
- AWS S3 RRS (低冗長化ストレージ (RRS) は Amazon S3 ストレージオプションであり、Amazon S3 標準ストレージよりも低いレベルの冗長性で、重要で再現性のないデータをお客様に保存することができます。RRS は、単一の施設内のデータの損失を維持するために設計されています。)
- ユーザーは、ライフサイクルルールを使用してオブジェクトをGlacierに移動しました。ユーザーは6か月後にアーカイブを復元するように要求します。復元要求が完了すると、ユーザーはそのアーカイブにアクセスします。以下のステートメントのうち、この条件で正しくないものはどれですか?
- アーカイブは、復元要求時にユーザーが指定した期間のオブジェクトとして使用できるようになります。
- 復元されたオブジェクトのストレージクラスは RRS になります (オブジェクトを復元すると、ストレージクラスは依然として Glacier のままになります。「アーカイブされたオブジェクトの復元」を参照)
- ユーザーは、更新された期間で新しい復元要求を発行することによってのみ、復元期間を変更できます。
- ユーザーは、RRS (復元) と Glacier (アーカイブ) レートの両方のストレージを支払う必要があります。
- 部門は、会社のログファイルから定期的なアナリティクスレポートを作成します。すべてのログデータは Amazon S3 で収集され、毎日の Amazon Elastic MapReduce (EMR) ジョブによって処理され、Amazon Redshift データウェアハウスの日次 PDF レポートと集計テーブルを CSV 形式で生成します。CFO は、このシステムのコスト構造を最適化することを要求します。Raw データのシステムまたはデータ整合性の平均パフォーマンスを損なうことなく、以下の選択肢のどれがコストを削減するか。(PROFESSIONAL)
- Amazon S3 の PDF および CSV データに対して、低冗長化ストレージを利用します。Amazon EMR ジョブにスポットインスタンスを追加します。Amazon Redshift にリザーブドインスタンスを使用します。(スポットインスタンスはパフォーマンスに影響します)
- S3 のすべてのデータに対して、低冗長化ストレージ (RRS) を使用します。Amazon EMR ジョブのスポットインスタンスとリザーブドインスタンスの組み合わせを使用します。Amazon Redshift にリザーブドインスタンスを使用する (スポットの組み合わせと保証のパフォーマンスで予約され、コストを削減できます。また、RRS はコストを削減し、データの完全性を保証します。)
- Amazon S3 のすべてのデータに対して、低冗長化ストレージ (RRS) を使用します。Amazon EMR ジョブにスポットインスタンスを追加します。Amazon Redshift にリザーブドインスタンスを使用する (スポットインスタンスがパフォーマンスに影響を与える)
- S3 の PDF および CSV データに対して、低冗長化ストレージ (RRS) を使用します。EMR ジョブにスポットインスタンスを追加します。Amazon Redshift にスポットインスタンスを使用します。(スポットインスタンスはパフォーマンスに影響します)
- 以下のオプションのうち、AWS RRS にコンテンツを格納するための適切な使用例はどれですか?
- ミッションクリティカルデータファイルの保存
- 使用頻度の低いログファイルの保存
- 再現できないビデオファイルの保存
- イメージサムネイルの保存
- 新聞の組織は、そのバックカタログを検索し、Java で書かれたウェブサイトを介して個々の新聞のページを取得することができるオンプレミスのアプリケーションを持っています。彼らは、jpeg (約 17TB) に古い新聞をスキャンし、商業検索製品を移入するために光学式文字認識 (OCR) を使用しています。ホスティングプラットフォームとソフトウェアは、現在の生活の終わりであり、組織は、AWS にそのアーカイブを移行し、コスト効率の高いアーキテクチャを生成し、まだ可用性と耐久性のために設計されたいと考えています。最も適切なのはどれですか。(PROFESSIONAL)
- 冗長性が低下した S3 を使用して、スキャンしたファイルの保存と提供、EC2 インスタンスへの商用検索アプリケーションのインストール、自動スケーリングとエラスティックロードバランサーの構成を行います。(RRS の影響耐久性と商業検索コストに追加されます)
- CloudFormation を使用して環境をモデル化します。Apache web サーバとオープンソース検索アプリケーションを実行している EC2 インスタンスを使用して、複数の標準 EBS ボリュームをストライプ化して、jpeg と検索インデックスを保存します。(EBS を使用すると、ファイルを保存する際にコストがかからない)
- 標準の冗長性を備えた S3 を使用して、スキャンされたファイルを保存して提供し、クエリ処理に CloudSearch を使用し、Elastic Beanstalk を使用して複数のアベイラビリティーゾーン間で web サイトをホストします。(標準 S3 および Elastic Beanstalk は、可用性と耐久性を提供, 標準の S3 と CloudSearch は、コスト効率の高いストレージと検索を提供します)
- 単一 AZ RDS MySQL インスタンスを使用して検索インデックスを格納し、JPEG イメージは EC2 インスタンスを使用して web サイトにサービスを提供し、ユーザークエリを SQL に変換します。(RDS は理想的ではありませんし、ファイルを保存するのに効果的なコスト、単一の AZ は可用性に影響します)
- CloudFront のダウンロード配布を使用して、エンドユーザーに jpeg を提供し、現在の商用検索製品をインストールし、EC2 インスタンス上のウェブサイト用の Java コンテナと共に、DNS ラウンドロビンで Route53 を使用します。(CloudFront はソースを必要とし、商用検索製品を使用することは費用効果がありません)
- 研究者は、Elasitc MapReduce クラスタのワンタイム起動を計画しており、コストを最小限に抑えるために彼女のマネージャーによって奨励されています。クラスターは、ゲノムデータの200を 100 Amazon EC2 インスタンスの合計で摂取するように設計されており、約4時間の稼働が見込まれています。結果のデータセットは、Amazon RDS Oracle インスタンスにアーカイブされるまで一時的に保存する必要があります。要件を満たしながら、どのオプションが最もお金を節約するのに役立ちます?(PROFESSIONAL)
- 取り込みと出力ファイルを Amazon S3 に保存します。マスターおよびコアノードのオンデマンドを展開し、タスクノードのスポットを配置します。
- マスター、コア、およびタスクの各ノードに対して、オンデマンド、RI、スポット価格モデルの組み合わせを展開することによって最適化します。アマゾンのGlacierにそれらをアーカイブするライフサイクルポリシーと Amazon S3 で取り込みと出力ファイルを格納します。(マスターとコアは RI またはオンデマンドでなければなりません。スポットにはできません)
- 取り込みファイルを Amazon S3 RRS に保存し、出力ファイルを S3 に保存します。マスターおよびコアノードのリザーブドインスタンスと、タスクノードのオンデマンドを展開します。(取り込みファイルの耐久性が必要です。スポットインスタンスは、コスト削減のためにタスクノードに使用できます。RI は、この場合にはコスト削減を提供しません)
- オンデマンドのマスター、コア、タスクノードを展開し、Amazon S3 RRS で取り込みおよび出力ファイルを格納する (入力は s3 標準にする必要があります)
Jayendra’s Blog
この記事は自己学習用に「AWS S3 Storage Classes – Certification(Jayendra’s Blogより)」を日本語に訳した記事です。
コメントを残す