Amazon CloudSearch
- CloudSearch は、AWS クラウドで完全に管理されたフル機能の検索サービスであり、検索ソリューションの設定、管理、拡張が容易になります。
- CloudSearch
- 必要なリソースを自動的にプロビジョニングする
- 高度にチューニングした検索インデックスを展開する
- 構成が簡単で、1時間以内に稼動可能
- 検索可能なデータをアップロードする機能
- データとトラフィックの自動スケーリング
- 自己修復クラスタ、および
- マルチ AZ による高可用性
- CloudSearch は Apache Solr を基になるテキスト検索エンジンとして使用し、
- 構造化および非構造化データのインデックス作成と検索に使用できます。
- コンテンツは複数のソースから入手でき、さまざまな形式、Web ページなどのファイルと共にデータベースフィールドを含めることができます。
- アルゴリズムステミング、辞書ステミング、ストップワード辞書などの索引付け機能をサポート。
- カスタマイズ可能な結果ランキングすなわち関連性をサポートすることができます
- テキスト検索、さまざまなクエリの種類 (範囲、ブールなど)、並べ替え、フィルター処理のためのファセット、グループ化などの検索機能をサポートします。
- 自動提案、強調表示、空間検索、あいまい検索などの拡張機能をサポート
- CloudSearch はマルチ AZ オプションをサポートし、同じリージョン内の2番目の AZ に追加のインスタンスを展開します。
- CloudSearch は、独自の検索環境を運用および管理する場合と比較して、TCO(総所有コスト) を大幅に削減できます。
CloudSearch 検索ドメイン、データ&インデックス
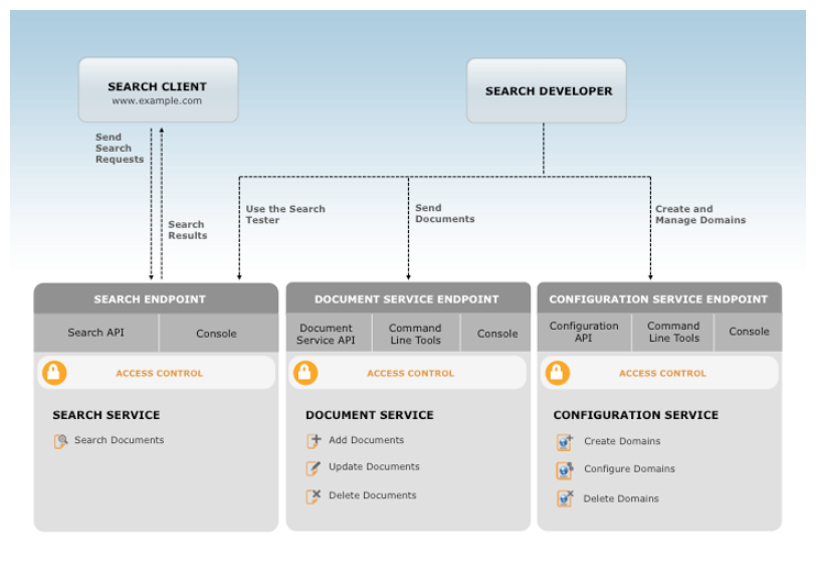
- 検索ドメインはデータコンテナであり、データを検索可能にする一連のサービス
- インデックス作成のためにドメインにデータをアップロードできるドキュメントサービス
- インデックス付きデータに対する検索要求を有効にする検索サービス
- ドメインの動作を制御するための構成サービス (関連性ランキングを含む)
- 検索ドメインは、あるリージョンから別のリージョンに自動的に移行することはできません。ターゲットリージョンの新しいドメインを作成し、構成してデータをアップロードし、元のドメインを削除する必要があります。
- インデックス化されたデータを検索可能にする
- REST ベースの Web サービス URL を通じて送信できます。
- JSON または XML 形式でなければなりません
- 一意のドキュメント ID と複数のフィールドを持つドキュメントとして表示され、必要に応じて検索することができます。
- CloudSearch は、ドメインに対して構成されたインデックスフィールドに従って、ドキュメントデータから検索インデックスを生成します。
- データの更新は、ドキュメントの追加、更新、および削除によって送信できます。
- セキュアで暗号化された SSL HTTPS 接続を使用してデータをアップロード可能
CloudSearch Auto Scaling

- 検索ドメインは2つのディメンションでスケーリングされます: データとトラフィック
- 検索インスタンスは、クラウド内の1つの検索エンジンであり、ドキュメントをインデックス化し、データのインデックス作成や要求の処理に使用する RAM と CPU リソースを有限で検索要求に応答します。
- 検索ドメインには、1つ以上の検索パーティション、1つの検索インスタンスに収まるデータの一部、およびドキュメントのインデックスが作成されるときに検索パーティションの数が変化することがあります。
- CloudSearch は、低レイテンシ、高スループットの検索パフォーマンスを実現するために必要な検索インスタンスのサイズと数を決定できます。
- 検索ドメインが作成されると、1つのインスタンスが展開されます。
- CloudSearch は、データのボリュームまたはトラフィックの増加としてインスタンスを追加することにより、自動的にドメインをスケーリング
- データのスケーリング
- CloudSearch は、データのスケーリングを処理します。
- データの量が1つの検索インスタンスを超える場合に、インスタンスのサイズを大きくすることによって垂直方向のスケーリング
- データ量が最大の検索インスタンスタイプの容量を超える場合、検索パーティションを使用した水平スケーリング
- インデックスパーティションを保持するために必要な検索インスタンスの数は、ドメインの幅と呼ばれることがあります。
- CloudSearch は、データ量が減少した場合に、検索インスタンスのパーティション数とサイズを削減します。
- CloudSearch は、データのスケーリングを処理します。
- トラフィックのスケーリング
- CloudSearch は、トラフィックのスケーリングを処理します。
- トラフィックの量が1つの検索インスタンスを超える場合に、インスタンスのサイズを大きくすることによって垂直方向のスケーリング
- 追加の処理能力を提供するために重複した検索インスタンスを展開することによって水平方向のスケーリングすなわち、パーティションの完全な数が複製される。
- CloudSearch は、トラフィックが減少した場合、検索インスタンスのパーティションとサイズの数を削減します。
- 重複する検索インスタンスの数は、ドメインの深度と呼ばれることがあります。
- CloudSearch は、トラフィックのスケーリングを処理します。
CloudSearch 検索機能
- CloudSearch は、構造化されたデータとプレーンテキストだけでなく、pdf、word 文書のような非構造化データの両方をインデックスと検索する機能を提供しています
- CloudSearch は、ドキュメントの更新のためのほぼリアルタイムのインデックス作成を提供
- インデックス機能には、
- トークン
- ストップ
- ステミング
- 類義語
- 検索機能には、
- ファセット検索、フリーテキスト検索、ブール検索式
- カスタマイズ可能な関連性ランキング、クエリ時間ランク式
- グループ
- フィールドの重み付け、検索、および並べ替え
- 他の機能
- オートコンプリートの提案
- ハイライト
- 地理空間検索
- 新しいデータ型: 日付、ダブル、64ビット符号付き int、LatLon
- ダイナミックフィールド
- インデックスフィールドの統計
- あいまいなフレーズ検索
- 項目ブースト
- すべてのフィールドタイプを検索する拡張範囲
- 関連性に影響を及ぼさない検索フィルタ
- 複数のクエリパーサーのサポート: シンプル、構造化、lucene、dismax
- クエリパーサーの構成オプション
AWS認定試験の練習問題
- 質問はインターネットから収集され、答えは自分の知識と理解に基づいてマークされます(これはあなたと異なる場合があります)。
- AWSサービスは毎日更新され、回答と質問はすぐに時代遅れになる可能性がありますので、それに応じて調査してください。
- AWSのアップデートのペースを追うためにAWS試験の質問は更新されないため、基礎となる機能が変更されても質問が更新されないことがあります。
- さらなるフィードバック、ディスカッション、修正を可能にします。
- 新聞社の組織には、公開されているカタログを検索し、Java で書かれた Web サイトを介して個々の新聞ページを検索することを可能にするオンプレミスアプリケーションがあります。 彼らは古い新聞を JPEG(約17TB)にスキャンし、光学式文字認識(OCR)を使用して商用検索製品に取り込んだ。 ホスティングプラットフォームとソフトウェアは現在のところ廃止されており、アーカイブは AWS に移行し、コスト効率の高いアーキテクチャを生み出し、可用性と耐久性を考慮して設計されています。 最も適切なのはどれですか?
- S3 を使用して冗長性を減らし、スキャンしたファイルを保存および提供し、EC2 インスタンスに商用検索アプリケーションをインストールし、自動スケーリングと Elastic Load Balancer で設定します。 (廃止が近づいている商用検索アプリケーションを再利用してコストの良い選択肢にはならない)
- CloudFormation を使用して環境をモデル化する。 Apache Web サーバーとオープンソース検索アプリケーションを実行する EC2 インスタンスを使用し、複数の標準 EBS ボリュームをストライプ化して JPEG と検索インデックスを格納します。(EBS ボリュームに JPEG を保存するのは費用対効果が低く、回答でもオープンソースソリューションの可用性には対応していません)
- 標準の冗長性を備えた S3 を使用して、スキャンされたファイルを保存して提供し、クエリ処理に CloudSearch を使用し、Elastic Beanstalk を使用して複数のアベイラビリティーゾーン間で Web サイトをホストします。(コスト効率の高い S3 ストレージ, 検索と高可用性と耐久性のある Web アプリケーションのための CloudSearch)
- 単一 AZ RDS MySQL インスタンスを使用して検索インデックスを格納し、JPEG イメージは EC2 インスタンスを使用して web サイトにサービスを提供し、ユーザークエリを SQL に変換します。(MySQL はコストとパフォーマンスのためのインデックスと JPEG 画像の痛みに理想的なソリューションではありません)
- CloudFront のダウンロード配布を使用して、エンドユーザーに jpeg を提供し、現在の商用検索製品をインストールし、EC2 インスタンス上のウェブサイト用の Java コンテナと共に、DNS ラウンドロビンで Route53 を使用します。(Web アプリケーションはスケーラブルではなく、CloudFront を介して jpeg ファイルのソースをいただきました)
リファレンス
- Amazon CloudSearch 開発者ガイド
- AWS Black Belt Tech Webinar 2016 〜 Amazon CloudSearch & Amazon Elasticsearch Service 〜 (SlidShare / オンデマンドセミナー)
Jayendra’s Blog
この記事は自己学習用に「AWS CloudSearch – Certification(Jayendra’s Blogより)」を日本語に訳した記事です。
コメントを残す